- Wednesday, 5 Dec 2012:
Accessibility Advent: support the escape key
- Tuesday, 4 Dec 2012:
Accessibility Advent: hitzones should fill their visible area
- Monday, 3 Dec 2012:
Accessibility Advent: strip leading spaces
- Sunday, 2 Dec 2012:
Introducing Accessibility Advent
- Wednesday, 12 Oct 2011:
On Resolution
- Saturday, 17 Sep 2011:
What Schonfeld should have written
- Monday, 11 Apr 2011:
Exceptional improvements
- Friday, 8 Apr 2011:
Client-side routing, the teenage years
- Tuesday, 22 Feb 2011:
Wisdom comes from deliberate reflection
- Sunday, 7 Feb 2010:
Exceptional HTTP status codes in Django
- Published at
- Wednesday 5th December, 2012
(Throughout Advent I’m sharing some hints as to how web developers can make my life as a speech recognition user easier.)
I wrote yesterday about how moving the pointer by voice works; it’s a bit cumbersome, so forcing voice users to go that route isn’t great. Here’s another example.
Modal windows are an old desktop interface method requiring a specific interaction (such as confirming an operation) before continuing with normal application use. More generally, user interface modes are different states of the interface where it will respond differently to the same input (mouse clicks, keystrokes or whatever). Web apps are increasingly using modal techniques; done poorly they are a pain for voice users.
Two examples. The first: Twitter. If you click on a Twitter username, you get a modal sheet about that user. Clicking outside, or on the close button, dismisses it. So does pressing escape. Twitter also has a “new Tweet” button top right that is almost the same – except that escape does nothing. By voice, pressing a key takes about a second – compare to the problems discussed yesterday with controlling the pointer.
Second example: Google Reader. This has pretty good keyboard shortcuts, so I spend most of my time in it navigating by macros, saying things like “next news story”, “view original” and so on. The trouble with voice recognition is that it’s imperfect, so occasionally it will hear one thing and recognize it as something else, which ends up as dictation, i.e. basically just random keystrokes. (I could shift out into something called Command Mode, which won’t generate normal dictation; however I usually only think about that once something has gone wrong.)
Three keystrokes in particular do big things in Reader: “u” and “f” change the screen layout (and can be repeated to switch back), and “e” starts the “email this story” feature, from which there is no return (unless you tab to the cancel button, or move the pointer to click on it). The escape key apparently isn’t used while this feature is running, and would make things much easier. (Also, the email interface is inline, rather than floating over the rest of Reader as Twitter does things, making it less obvious that the feature is modal. That only confused me the first time, however.)
Simple rule: for interface modes, provide keyboard shortcuts.
Simpler rule: support the escape key.
Note this isn’t just for web apps; sites like Mother Jones have taken to using a floating layer to ask for donations. While it isn’t strictly modal (the site behind scrolls and links still work), since it obscures part of the content it’s effectively the same issue. Escape should close these kinds of things as well (or they should disappear automatically after a while – as advertising often does).
- Published at
- Tuesday 4th December, 2012
(Throughout Advent I’m sharing some hints as to how web developers can make my life as a speech recognition user easier.)

It’s probably fairly obvious how dictating text into, say, a mail client works, and even how voice commands to invoke menu items and keystrokes fit together. Let’s look at how voice control of the pointer works in Dragon. There are two different modes of operation, although they can be mingled, plus commands for clicking buttons, and pressing and releasing which enable dragging.
The first is the Mouse Grid: start by dividing the screen into a 3x3 grid, let the user select a grid square then centre the pointer in that square and subdivide into another 3x3 grid. Repeat until the user has moved the pointer to where they need it. You do this by saying things like “Mouse Grid / 1 / 3 / 7 / Close Mouse Grid”. (If you have multiple monitors, the first digit you say selects the monitor.)
The other is relative movement, by saying things like “Move Mouse Up And Left 3 Centimetres”. (You can also use inches, and “points”. None of them is a particularly obvious unit when staring at the screen; I tend to use centimetres.) If you aren’t sure about the distance you can go a bit more interactive, with “Move Mouse Up And Left”, watching it move, maybe saying “faster” and “slower” to control the speed, and finally “stop” when you’ve reached your destination.
My rule of thumb is to use relative for short or repeated movements (because going back and forth by a fixed amount is easy once you know what that distance is), and Mouse Grid for everything else.
Okay, fine. It’s a little cumbersome, but it works. What can we find to make it worse, so you can not do that and generally stop bugging me?
Remember Fitts’ Law: wider, closer things are faster to acquire. Closer doesn’t really apply here (except that longer distances are harder to guess, so relative movement is more likely to miss). Wider gives a margin for error, which applies with both relative and Mouse Grid movements, suggesting Fitts’ Law will apply here; although I haven’t actually checked for research confirming that, anecdotally it feels right based on my experience.
So how can you confound Fitts’ Law, beyond making your buttons tiny? By masking how tiny your buttons are. Here are two links. Which is bigger?
The left one is div > a with padding on the div. The right one is div > a with padding on the a. They look the same. They aren’t. Again, with an outline on the anchors:
(Apologies for the shoddy CSS; I didn’t have the patience to think it through any better.)
This affects everyone, but mouse users are close to where they need to be and can just slide around to find the hitzone. This kind of “looking with the mouse”, looking for the cursor to change or similar isn’t practical for voice users; speculatively moving a bit and trying again ("Move Mouse Right / Stop / Mouse Click") is much more expensive. Trying again with Mouse Grid is even worse.
Simple rule: hitzones should fill their visible area.
The formula at the top is for the Accot-Zhai steering law, a path-following generalisation of Fitts’ Law which should model using the Mouse Grid well.
- Published at
- Monday 3rd December, 2012
(Throughout Advent I’m sharing some hints as to how web developers can make my life as a speech recognition user easier.)
There are any number of strange effects of using speech recognition to drive a computer, but the one that affects almost everything I do – and that I forget most often that I have to take account off – is leading spaces. Dragon doesn’t always notice when you’ve moved between input elements, and when it doesn’t it assumes any dictation continues the previous sentence. This results in a leading space in the new input.
You can imagine all sorts of situations where this is a pain, but the one that annoys me most is when I have to put in credit card or banking details. (It can also be a problem with CAPTCHA, although usually less than figuring out what the messed up letters are in the first place.)
I’ll note in passing here that, yes, this is a software problem at my end: it should be possible for Dragon to get this right. Indeed if I remember correctly, Dragon Naturally Speaking on Windows doesn’t have this problem, and for that matter if I used Safari on Mac there are commands that can help navigate text inputs while telling Dragon what’s going on. I dislike Safari sufficiently that the alternative would be to go back to Windows, where Dragon Naturally Speaking provides better integration with Internet Explorer.
The leading space issue doesn’t just crop up with web forms – Glee Box itself suffers from it, for one, and sometimes the 1Password unlock screen gets a rogue space as well. I can say “no space” before a word to prevent the leading space, but I don’t always remember. I’d love it if web forms just stripped leading spaces so this never bit me, but it’s particularly annoying when it interacts with naïve validation.
Leading spaces should not be considered invalid in numeric fields. Most string to number conversion functions will happily skip them, and so should your validator, be it a regular expression or something more esoteric. This is equally true whether your validation runs on the backend or front-end (and, sidebar, it should run on both); if the latter then there’s another problem, which banking sites are particularly prone to run foul of.
Long numbers are hard to type in accurately (they’re easier to dictate, as it happens). One way of making things easier is to split them into shorter sequences – for instance, your credit card probably has four groups of four digits on the front instead of just one sixteen digit string. This is fine.
Similarly, to allow people to verify that they typed a number in correctly, some sites use multiple input boxes, building the single number in code somewhere. I haven’t seen this often with credit cards, but it gets used for software registration numbers a lot, and some banks split up the authentication codes coming in from PIN-based token generators, such as Barclays’ PINsentry.
As a web developer you see a requirement for two boxes each taking four digits, so you set the maximum length (maxlength) of each input to four.
[1234] [5678]
Then I come along with my leading space problem and this happens:
[ 123] [5678]
Actually it’s usually worse than that, because you’re clever so you advance the focus once there are four characters in the first input:
[ 123] [4567]
Then some other clever developer adds client-side validation to the form. One of two things happens, depending on where the focus is left. Most commonly, the focus seems to end up on a help link explaining what went wrong:
[ 123] [] ERROR!
If I’m lucky I can then tab back to the first input and try again. It’s around this point that I want to punch someone. (For reasons I don’t understand, inputting numbers in this stop-start staccato fashion is considerably more stressful than dictating prose and then correcting it.)
So what should happen? With client side validation, killed the leading space when it appears. Without (and this is going to upset some people), set the input maximum length to one more than you’re looking for (five, in this case) – and then deal with this properly in the backend so an input like the following still works:
[12345] [678]
Using client-side validation here is a Very Good Thing, clearly.
But wait, it gets worse. Say you read the above and decided one big input is better (as most people do for credit card numbers, for instance). You allow Allow the slightly larger input maximum length, strip any leading space, and then reuse that code when building an e-banking setup system, where an authentication code gets mailed through the post to confirm the user is who they say they are. You parameterize your widget based on code length. Two years later someone rolls it out for codes the same length as US phone numbers. Dragon helpfully formats my code as a phone number:
123-555-6789
So you should probably strip internal hyphens, and make the input maximum length even longer – in fact, I’m beginning to wonder if exact input maximum lengths are ever useful.
- Published at
- Sunday 2nd December, 2012
Recently I’ve noticed a particular kind of rage growing within me, a rage that has me tweeting bile and involuntarily punching imaginary developers sitting next to me. It is the rage caused by people who don’t think about accessibility when building (mostly) websites.
There are a million sites and articles that make the case that you should care about accessibility – features and techniques that help users of “assistive technology” – usually from a legal (local legislation requires you make efforts towards accessibility) or economic (you can make more money, yay!) standpoint. My argument is different.
I use assistive technology. When I encounter a poorly built website or piece of software, I wanted to punch the people involved. Eventually I won’t be able to constrain myself.
No one really wants that, so this Advent I’ll be giving some hints on how you, as a web developer, can make my life easier. I use Dragon Dictate for Mac, which uses the same voice recognition engine as Dragon Naturally Speaking for Windows; my advice will sometimes be specific to Dragon, and more commonly only considered from the point of view of speech recognition users – I’ll be trying to explain why these things are important to me, as well as what you should do. Nonetheless, the vast majority of things that people commonly get wrong are either general accessibility mistakes, or subtle details that are unlikely to cause problems for any other users if implemented the way I think they should be. If you disagree, or I’ve just got something utterly wrong, then let’s talk so I can improve my advice.
I’ll be publishing these weekdays during Advent. They aren’t in any particular order. I may forget to update the following list every day:
- Published at
- Wednesday 12th October, 2011
As soon as you scale beyond one host — in a data centre or in the cloud — you start needing a way to resolve services. Where previously every service — your database, your key-value store — was local to your application, now some will be on another host, and your software needs to find it.

Services separated across two hosts
Probably the most common form of resolution currently is the Domain Name System, or DNS. (DNS is used as part of Active Directory, which you’ll probably use if you run a Windows-based data centre.) Using DNS has a number of advantages:
- wide support; every operating system you’re likely to use will have DNS support out of the box
- distributed, fault-tolerant, and secure
- you’re already using it (for mail routing, web routing and so forth)
Inside the data centre, you probably wind down the TTL (time to live) on DNS records, and either use dynamic DNS updates to change them or some sort of central control panel — so when you want to switch your primary database server, you flip a switch, and the hosts look up the new record inside a few seconds, and on we go. The main downside, beyond setting up all the pieces (which isn’t hard, but so many people are allergic to simple sysadmin tasks these days) is that you need somewhere to flip the switch from. Building that in a distributed fashion is hard, and most people don’t bother. (However you don’t flip the switch very often, and you can easily set things up so that even if the switch machine breaks, the rest of the system keeps on working.)

Switch between data servers using DNS in the data centre
Enter the cloud
From a certain standpoint, using cloud hosting such as Amazon EC2 makes no difference to this picture. In the cloud it’s more common to tear down and replace instances (hosts), but the shift between different available instances can be managed using configuration systems such as puppet or chef to update DNS easily enough. There is, however, a better way.
Let’s take a step back for a moment and ask: what are we trying to do?
What we want is a way to resolve from function to host. DNS allows us to do this by naming functions within a zone, but in the cloud there’s actually an existing mechanism that closely models what we want already: security groups. (Security groups seem to be only available with Amazon EC2 at the moment; it’s possible that you can do similar things using metadata keys with Rackspace, although you’ll have to do more work to tie it into your explicit iptables configuration.)
Security groups are a way of controlling firewall rules between classes of instances in the cloud. So it’s not uncommon to have a security group for web access (port 80 open to the world), or database access (your database port open only to those other security groups, such as your web servers, that need it). Although they’re called security groups, the most logical way of using them is often as functional groups of instances.

Two security groups in the cloud
Since you already need to define instances in terms of their security groups, why not resolve using them as well? The Amazon APIs make it easy for instances to find out which security groups they are in, as well as for other instances to look up which instances are in a particular group. Hosts can even be in multiple groups, allowing them to perform multiple functions at once.
This is how elasticsearch performs cluster resolution for EC2: you give it Amazon IAM credentials that can look up instances by security group, and a list of security groups, and elasticsearch will look for other instances in those security groups, bringing them into the cluster. Spin up a new elasticsearch instance in the right security group, and it joins the cluster automatically.
cloud:
aws:
access_key: AKIAJX4SKZVMGKUYZELA
secret_key: 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
index:
translog:
flush_threshold: 10000
discovery:
type: ec2
ec2:
groups:
- airavata
gateway:
recover_after_nodes: 1
recover_after_time: 2m
expected_nodes: 2
bootstrap:
mlockall: 1
We do the same thing at Artfinder for our web servers to resolve database instances and so on.
AWS_REGION, AWS_PLACEMENT = get_aws_region_and_placement()
TPHON_HOSTS = find_active_instances("tphon", AWS_REGION)
DUMBO_HOSTS = find_active_instances("dumbo", AWS_REGION)
In some cases, you need to choose only one machine to use out of several in the security group, perhaps because you have several different instances with the same data available, or perhaps because you’re bringing up a new instance which isn’t yet ready. You could test connect to each one to find a genuine running service, or you could use EC2′s facility for tagging instances. We use a tag of af-status=ready on anything that’s in service, and we can check that when finding database instances, or when figuring out which machines should be attached as web servers to our load balancers.

A new web server instance that isn't yet ready for use
We do this with a very simple filter on top of the security group-based instance resolution code:
from awslib.ec2 import instances_from_security_group
def find_active_instances(security_group, AWS_REGION='us-east-1'):
def active(instance):
if instance.state!='running':
return False
elif instance.tags.get('af-status', None) != 'ready':
return False
else:
return True
return filter(
active,
instances_from_security_group(
security_group,
region=AWS_REGION,
aws_access_key="AKIAJX4SKZVMGKUYZELA",
aws_secret_key="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",
)
)
Tags have a considerable advantage over security groups in that they can be altered after you spin up an instance; you could in fact use only tags to resolve instances if you chose, although since you still need to provide firewall rules at the security group level, a mix seems best to us.
Tags allow us to have a security group for all our backend data storage services — to start with everything’s always on one host — and then migrate services away smoothly, simply by moving tags around. (Obviously there is some complexity to do with replication as we migrate services, or some downtime is required in some cases.) We don’t have to deploy code, and we don’t have to wait for DNS changes to propagate (even with a low TTL there’s a short period of time to wait) — we just flip a switch, either in Amazon’s web console or via the EC2 API, both of which are already distributed and can be accessed from anywhere given the right credentials. Most crucially, the web console is already written for us — we have a small amount of code to take advantage of security group and tagging for resolution, and that’s it.
In actual fact, our running instances don’t re-resolve continually, since that’s a performance hit; but we can reload the code on command from fabric, from anywhere, as well, and they’ll resolve the new setup as they reload. Flipping a service from one machine to another takes a few seconds, on top of whatever work has to be done to migrate data.
Configuration management
In general if you make the same configuration change twice you’re doing it wrong. Configuration management allows you to specify how all your hosts are set up — packages installed, services running, everything — so you can apply it automatically to new hosts, or upgrade existing ones as configuration changes. Two of the most common configuration management systems today are puppet and chef — we use puppet. The crucial part when running several different types of host is to figure out which configuration to apply for a given host. One way is to use hostnames, or MAC addresses, but this doesn’t work well in the cloud where you can’t predict anything about an instance before you build it. However you can control what security group it’s in; we have a custom fact that looks up the security groups an instance is in and matches that to a configuration.
require 'open-uri'
groups = open("http://169.254.169.254/2008-02-01/meta-data/security-groups").read
groups = groups.split("\n")
groups = groups.select {|g| g != 'ssh-access' }
if groups.size > 0
sec_group = groups.first
Facter.add("ec2_security_group") {
setcode { sec_group }
}
puts "SECURITY GROUP #{sec_group}"
end
We combine this with the Ubuntu EC2 AMIs’ user-data init script system to automatically puppetize new instances on startup. For instance, to bring up a new search server we just do:
fab new_airavata:puppet_version=2011-10-12T10.42.01
A few minutes later, our search cluster has a new member, and can start redistributing data within it. (Although it uses fabric, it’s actually just python using boto, an EC2 library. We use fabric to perform management tasks on existing instances, so it makes sense to use it to fire up new ones as well.)
It’s a bit more work to bring up a new webserver (currently we like to test them rather than putting them automatically in rotation at the load balancer), and database servers tend to be the hardest of all because they require hostnames to be set in textual configuration for things like replication configuration — although this can be managed with puppet, and we’ll get there eventually.
A slightly crazy idea
The big advantage of DNS over security group resolution is the ubiquity of support for DNS lookups. Since this goes right down into using DNS hostnames for resolution within configuration files (such as for replication setup, as mentioned above), it might be helpful to run a DNS server that exposes security groups and tags as a series of nested DNS zones:
; Origin is: ec2.example.com
1.redis.tphon IN A 10.0.0.1
2.redis.tphon IN A 10.0.0.2
3.redis.tphon IN A 10.0.0.3
1.postgres.tphon IN A 10.0.0.3
2.postgres.tphon IN A 10.0.0.4
1.readonly.postgres.tphon IN A 10.0.0.5
2.readonly.postgres.tphon IN A 10.0.0.6
We actually already do something similar for generating munin configuration, and it could be done entirely by a script regenerating a zonefile periodically; if anyone writes this, it’d be interesting to play with.
In summary
Although DNS is the most obvious approach to resolution on the internet, there are other options, and in Amazon’s cloud infrastructure it makes sense to consider using security groups and tags, since you are likely to need to set them up anyway. It takes very little code, and is already being adopted by some clustering software.
- Published at
- Saturday 17th September, 2011
Hopefully signalling the end of the dithering over whether TechCrunch will remain an entertaining, bitchy and sometimes accurate tech biz gossip site (Heat for the lives of web companies) or begin its gradual slide into tedium and obscurity (The New York Times for…well, for pretty much anything), newly-minted Editor-in-Chief Erick Schonfeld last night publicly accepted Paul Carr’s equally public resignation. It won’t actually be the end of the story, but a standard has been set, on both sides, and with Arrington off worrying about all the things VCs worry about and Carr indulging himself as only the unemployed can, the story at least should have reached a point where the majority of us can just ignore it without undue effort.
But Schonfeld missed a trick in writing such a dry acceptance. Now is the time, after all, to establish the new voice of TechCrunch, which is inevitably going to be different; he could also be taking concrete steps to demonstrate his independence from Arianna OnLine. So here’s what he should have written.
Disclosure: I'm an investor in Paul Carr, in that I've sunk money in two of his past projects. Although I probably made it back by working on Diageo campaigns.
For the last couple of weeks people have painted me variously as evil or inept, a mastermind or a puppet. I’ve never really thought of myself as either, but clearly I have to make a choice. Okay, then: I’ll be evil.
Paul Carr, one of our columnists who was hired for his grandstanding ways and has recently joined the hoardes outside the gate who just don’t understand my evil vision, has decided to fall on his own sword and quit very publicly on TechCrunch. I’m sorry, Paul, but that’s not acceptable.
Paul’s resignation post reads like the brave stand of a man of principle, but the truth is that Paul doesn’t really know what he is talking about. Only the evil genius has principles, long developed as he apprenticed under others. Henchmen can only have loyalty. Of course Carr thinks he is somehow being loyal to Mike, but that’s pointless. You can only have loyalty to someone who is there: henchmen can’t retain loyalty to someone playing the golden harp. They don’t have the imagination.
Naturally there will be changes as I take over the reins and put all the minions back in their traces (for instance, I’m tightening the use of language throughout everything we do, starting with the title: we’re now just CRUNCH, all in capitals like any proper evil organisation). I tried to reach out to Paul and was hoping to have an honest conversation about his future at CRUNCH (probably in Department III). Instead, he blindsided me with his post by publishing it as I was laughing insanely while playing with my pet shark.
In any other organisation, Paul would have been dealt with long ago. And his post would be taken down. But I will let it stand. When Paul was hired, he was promised that he could write anything and it would not be censored, even if it was disparaging to TechCrunch. I will still honor that agreement. But obviously there are forms I have to go through: I’ve changed the locks at CRUNCHQ, I’ve told all the other henchmen (and women) that Paul is a potential trouble source, and that they should disconnect from him. Also, I don’t want to brag, but I called in a couple of favours and…well, let’s just say that Paul probably shouldn’t go anywhere near Reno for a few years.
I am also not going to get into all the details of what happened behind the scenes during the drama which unfolded in the past few weeks here. But I will say this: to suggest that Arianna appointed me editor single-handedly is untrue. It took me weeks of preparation, thousands of dollars in bribes, and the tactical seduction of a judge on the Second Circuit. There must have been at least six hands involved. Possibly seven if we include a clerk hitting the light switch at the wrong time.
So I think we’ll all just have to agree to disagree on that one. Paul, you may think your hard work under Mike entitled you to certain benefits such as the right to leave at a time of your chosing. But when one chief succeeds another…well, we all know what happens to those who speak up for the old regime. So in fact I don’t have to accept your resignation; that was just you publishing your exit interview. In fact, if you think back carefully to that time when you “decided” you wouldn’t stay if Mike’s wishes weren’t honoured…your Diet Coke tasted a bit funny that night, didn’t it Paul? And when you went to bed, was your head spinning with rage, or with something else? I was there, Paul. I was there.
- Published at
- Monday 11th April, 2011
A while back I released a Django extension that makes it possible to raise exceptions for any HTTP status code. At the time this was mostly interesting to enable raising 403 Forbidden consistently; since the release of Django 1.3, and the introduction of class based generic views, this becomes more useful.
I’ve just uploaded a new version to PyPI which provides basic support for raising redirects as exceptions (basically, it does the exceptional processing even with DEBUG=True). At Artfinder I’m using it to implement slug redirects, where I’m overriding SingleObjectMixin.get_object to cope with slug changes without breaking old links; there are undoubtedly other useful things that can be done in a similar way.
At some point in the future, hopefully in Django 1.4, you’ll be able to achieve the same effect with some built-in support, but for the time being django_exceptional_middleware is still useful.
- Published at
- Friday 8th April, 2011
When I wrote about hashbangs, deep linking and ghettoised browsers, I genuinely thought I’d be able to punch out the second article within a couple of weeks. I failed utterly, due to a combination of illness, my company decloaking its new website, and a fair dose of general uselessness. But here we are again.
One of the main things I tried to do last time was to point out the problems that hashbangs bring; but with some common sense, namely that sometimes you have to go down this route. Since hashbangs are a way of mitigating the problems associated with client-side routing (CSR), the issue becomes: what are the benefits of CSR?
CSR does one thing, and one thing only: it allows you to change content on a web page without forcing a complete page load. This can be used in a couple of significant ways:
- Protect client-side state (eg: long-running client side processes such as media players) from being disrupted during the page load
- To ensure that the client interface remains responsive through loading new content
In fact, the second is in some ways just a particular use of the first, although in practice they’re significantly different and so should be treated separately.
Enemy of the State
A page load wipes out a whole bunch of stuff: all your Javascript variables are gone, the whole DOM is thrown away and another one built (even if the vast majority of the resultant DOM is identical to the previous page), and any plugins and embedded media are unloaded. There are various things you might be doing that this will upset, but one jumps out immediately: playing audio.
I hope the music plays forever
If you have an audio player on a site, I think it’s pretty obvious that you don’t want the playback interrupted every time you click on a link or otherwise move around the site. If you put the audio player in the page and don’t use CSR, then page loads will do just that, and we can all get behind the idea that this is a bad thing.
Now back in April 2010 I, and a bunch of /dev/fort folk, came together to do some work for a client we cannot name, but which might have had something to do with the music industry. Naturally, one of the things we built into the prototype we made was an audio player; and being somewhat contrary folks, and because we conveniently had a Ben Firshman to hand, we decided we wanted an audio player that didn’t require client-side routing.
(Actually, this was pretty much an essential for us to do what we wanted in the time available; with three designers and nearly a dozen developers creating and refining things as fast as we could, the idea of sitting down at the beginning and building out a CSR framework, then requiring everyone create work that could be dropped into it, really didn’t appeal. By avoiding the issue, we were able to have people treat every page they built as just another normal webpage; and Ben got to do something cruel and unusual in Javascript, which always makes him happy.)
And Ben managed it. The player itself lived in a pop-out window, with a Javascript API that could be called from other windows on the site so they could contain the media player controls you expect, showing what was playing and where it had got to, synchronised across any and all windows and tabs you had open. Even better, when you played a video, the audio player would be paused and unpaused appropriately. Finally, if due to some confusion or bug more than one player window was opened, they’d talk amongst themselves to elect a single ‘master’ player that would take command.
So it’s possible; but I wouldn’t recommend it. Mainly, the pop-out window is a bit ugly, and may conflict with pop-up blockers thus preventing you from hearing any audio at all, page loads or not. Secondly, the code gets quite complicated, and doesn’t really seem worth it if your site’s main aim is to play music, as say The Hype Machine or thesixtyone are doing.
The only thing I can think of in its favour is that it provides an obvious screen location for the active component of the player (be it Flash or whatever), which might help me out because for reasons unknown The Hype Machine never actually plays me any music at all on Safari. But putting up with ugliness and code complexity so that I can debug your site for you really doesn’t seem like a good trade-off.
This is the point that Hype Machine’s Anthony Volodkin made when he weighed in on the matter. He pairs it with some comments about UX that are disingenuous but not entirely wrong, as we’ll see later.
There is another point I’d like to make here, though: both Hype Machine and thesixtyone behave terribly if you open multiple tabs or browser windows. The lack of centralised player means that each tab will play independently of and ignoring the others, which means multiple songs playing over each other. If you rely on tabbed browsing, this is a bit upsetting (almost as much as things looking like links but not actually acting like them; note in passing that this is nothing to do with CSR, and that all of Twitter’s links on their site are real links, albeit using hashbangs). On the plus side, Ben has been thinking of writing a library to support the single-controller model he built, which would make this kind of thing much easier.
Other stateful enterprises
While preparing this article, I made some notes on two other reasons you might want to persist the state of the page (except for the interface responsiveness issue we’ll come to shortly). However both ended up with a question mark by them; although they seem perfectly sound to me in principal, I can’t think of anything significant that both has a need for one of them and has a need for deep-linking. Since I’m mainly interested in the intersection of good effects and bad effects of CSR with hashbangs here, these aren’t so interesting, but I’ll list them briefly for completeness.
computation: if you’re doing lots of work in the client (perhaps in Web Workers, or by doing sliced computation using setTimeout) then you don’t want the page to change underneath you. However in most cases the primary context isn’t going to change, so there’s no good reason for the URL to either, and you don’t need CSR so much as a way of stopping people from moving off the page, and there are already approaches to that. (Google Refine might do a fair amount of processing, but it doesn’t need a new URL except for each project; similarly Google Docs or similar only needs a new URL for each document. There’s probably some interesting corner cases here I haven’t considered, though.)
games: it occurs to me that you may want to have a web game with addressable (and hence linkable and sharable) sections that needs to keep client-side state. I suppose strictly this becomes either an issue of computation or interface responsiveness (or just not wanting to reload a chunk of state from the server, local storage or cookies), and in any case I can’t think of anyone actually doing this at the moment. (Of course, I’ve never played Farmville; those kinds of games might well benefit.)
Don’t Make Me Think
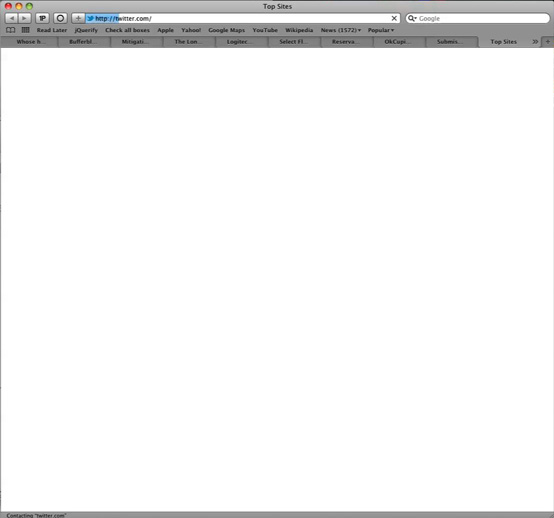
There’s a huge problem with web browsers as they currently work, which is that at some point between clicking on a link and the next page loading there’s a period where the window behaves as neither of the pages. If you’re lucky, the next page loads really quickly, and you don’t notice it, but there’s always a period where you can’t click anything, and sometimes can’t even see anything. Let’s illustrate this by loading Dustin’s tweet that I demonstrated with last time.
We see the new page start to load; at this point in most browsers the old page is still responsive.
But then we get a white page briefly.
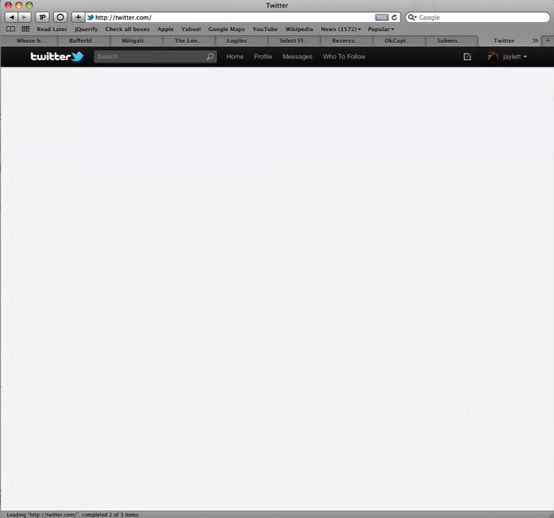
Then we get the Twitter HTML coming in…
…and finally Twitter’s Javascript CSR loads the contents of my timeline.
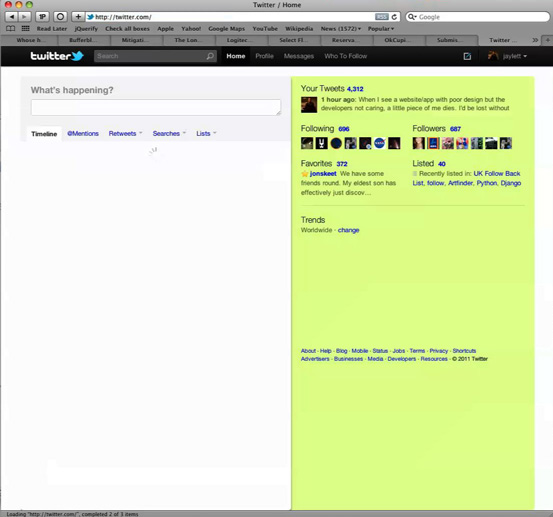
This actually happens in parallel to populating the right-hand side of the page, so the order that things appear isn’t fixed.
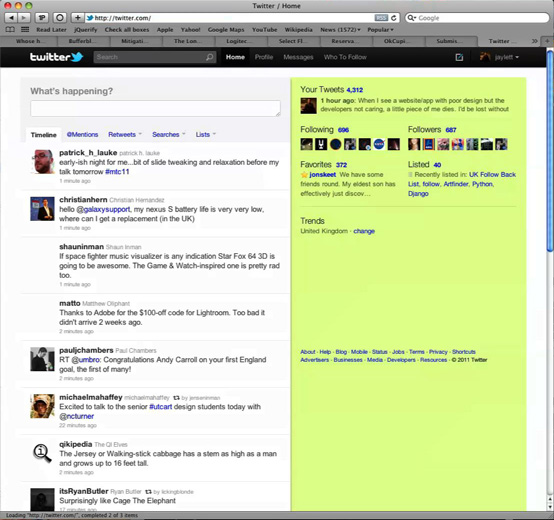
The entire thing took about a second for me as I recorded it as a video just now; it’s not a huge problem unless you have high latency or low bandwidth, and of course we’ve all learned to put up with it. However it is a genuine concern, as the longer something takes the more likely people are to get distracted during it.
I remember a much-touted point about an early version of the score writing software Sibelius was that every operation you could do, plus any redrawing of the screen, would be done in under a tenth of a second, which was supposed to be fast enough for people’s train of thought to be uninterrupted.
A brief diversion on distraction
I spent some time trying to find a reliable reference for the “tenth of a second” claim with no luck, although I’m guessing it related to the belief that it approximates the human reaction time (as noted critically by Wikipedia, for instance, although their article on mental chronometry does a better job). If you’re interested in human reaction time, there’s a 1982 article by Grice, Nullmeyer and Spiker which you can read for $12 or finding a student and buying them a beer.
Whatever the actual time required to interrupt a chain of thought, it’s clear that reducing the time of operations yields benefits. Google did some research in 2009 which can be taken to show that slower page loads result in less engagement with your site. (That’s not actually what it shows, but the paper itself is a single page without any detailed data to work with, and no discussion of confidence intervals; however it does show some impact on repeat engagement with Google Search based on slower page loads, and it marries sufficiently with common sense that we can probably go with the assumption that slow is bad until proven wrong.)
A brief diversion on latency
The Google paper talks about increasing the latency of search results, which informally means the time taken between doing something and seeing the result. Very roughly, an increase in latency is the same as increasing delay, as seen in this awesome cartoon.
Often when we’re talking about the web latency means network latency, which is the time between a computer (say a web server) sending some information (say a web page) and another computer (say your laptop) receiving it.
We usually measure network latency in milliseconds (ms), and they can range from very close to zero (for computers connected directly to yours) up to hundreds of milliseconds (say between one computer in London, UK and another in Perth, Australia). Between two computers about a mile apart in London, I see a round trip time (RTT) of about 22ms, giving the latency as about 11ms. From one of those computers to api.twitter.com gives an RTT of about 156ms, meaning 78ms latency.
And back to the topic at hand
Page loads on the web are generally slower than a tenth of a second; you’re only going to get that kind of speed out of the web for small pages from sites that are pretty close to you on the network (because of how brand new TCP connections work, you need a latency of under 25ms, and that’s not counting any time taken by the web server to process your request, or the web browser to render your page). Even 200ms is difficult to achieve for even small pages (50ms latency isn’t difficult when you’re within mainland US, but becomes difficult if you’ve got a lot of customers overseas and need to serve the traffic out of one data centre). Since Google were talking about 100-400ms showing a reduction in engagement, this has to be a serious consideration for anyone acting at scale (early-stage startups are more likely to be worried about getting more features up, and getting more users to play with them).
So the stage is set for us to introduce CSR to the problem. By asynchronously loading in new content rather than forcing an entire page load, we should be able to reduce the amount of data we have to transport, which might get us in under 400ms or even lower, but just as importantly, the interface remains completely functional throughout.
Don’t Make Me Wait
There’s a bit of an assumption going on here: that a responsive interface is enough to salve slow-loading content. In general this won’t be true (the fanciest interface probably won’t distract from taking ten minutes to load an image), but it would seem reasonable that there’s going to be a sweet spot where it’s better to spend time and effort on making the interface more responsive by using asynchronous loading than to spend the same time and effort trying to improve raw loading speeds.
After all, if a user decides they didn’t want something after they’ve asked for it but before it’s loaded, they just click somewhere else, and another async request will be fired off. Eventually something they’re interested in will load, unless you really can’t deliver content remotely fast at all.
A lot of people have grouped this under either “UX” or “performance”, which is unfortunate because they’re already both quite overloaded terms. I prefer to be precise about it, and say that the advantage here is around responsiveness, but we’re all getting at the same thing here. We want people to stay on our sites and keep on clicking around until, hopefully, we get to make some money, or kudos out of it, or at the very least get to stand next to celebrities and pretend we’re cool.
We’re not there yet
One of the dangers of imprecision is the conflation of different issues. You’ll note that CSR isn’t required for asynchronous loading of content at all; CSR is a way of making that content addressable by giving it a link that can be shared around. However not all content needs to be addressable.
I like to think of there being primary content, the “thing” you’re looking at, and secondary content which either relates to it in some way or is helpful in general. In terms of Twitter, primary content is the main timeline, searches, other people’s timelines, your followers and so on: the left-hand side of the web interface. Secondary content includes everything that goes in the right-hand panel: trending topics, favourites, lists you’ve been added to recently, and the conversation-ish view that pops up when you click on a tweet in the timeline. Secondary content can in some ways be considered to transclusion: including content within separate content, providing we talk quietly and don’t wake Ted Nelson.
When you don’t separate primary and secondary content, you wind up making mistakes; for instance, Ben Ward falls into this trap:
The reasons sites are using client-side routing is for performance: At the simplest, it’s about not reloaded an entire page when you only need to reload a small piece of content within it. Twitter in particular is loading lots, and lots of small pieces of content, changing views rapidly and continuously. Twitter users navigate between posts, pulling extra content related to each Tweet, user profiles, searches and so forth. Routing on the client allows all of these small requests to happen without wiping out the UI, all whilst simultaneously pulling in new content to the main Twitter timeline. In the vast majority of cases, this makes the UI more responsive.
This is misleading; the “small pieces of content” are generally pulled in without CSR, because the small requests aren’t the primary content of the page.
Here’s the thing. Primary content should be addressable; secondary content needn’t be. So secondary content isn’t going to benefit from CSR, and hashbangs don’t apply. (Twitter doesn’t make a hashbanged link for “your timeline with Dustin’s tweet highlighted”.) The only real similarity between them is that, with CSR, we can now load both asynchronously.
I argued last time you should consider not using CSR on “core objects” if you want a “safe” solution; these core objects are the same thing as primary content. But since CSR only benefits primary content, the conservative approach is never to use CSR at all. But we knew that; the interesting question is when you should use CSR.
The Tradeoff
The answer, as should be clear by now, relies on the relative importance of interface responsiveness compared the problems of limited addressability. It really needs considering on a case-by-case basis, and the trade-off relies on:
- how common an action is it?
- how fast is a complete page load compared to asynchronously pulling in just the new content, in the case of that action?
The former is down to a combination of UX design and user behaviour; with Twitter I know that I don’t often move far from the timeline, although I’d love to see hard data coming out from them about this.
For the latter, we have to start looking at performance. We’ll start by just looking at page sizes; but that’s for yet another separate article. I’ll try to complete it faster than this one.
- Published at
- Tuesday 22nd February, 2011
The latest flurry of doom-saying to hit the web is over the use (and particularly twitter’s use, although they’re not alone by any means) of “hashbangs”. This just means URI fragment identifiers that start with ! (so the URI displayed in the browser contains #!), and then using Javascript to figure out what to load on top of the basic HTML to give the desired content.
Twitter have been doing this since they rolled out #newtwitter, their application-like refresh of their website back in September of last year; the root of this sudden interest seems to be Mike Davies’ Breaking the Web with hash-bangs, with the negative side picked up by people as diverse as Jeremy Keith in the charmingly-titled Going Postel and Tim Bray with Broken Links. The flip side, supporting the use of hashbang (although generally with caveats, since pretty much everyone agrees they should be a temporary hack only) is also widespread, with one of the most straightforward rebuttals being Tom Gibara’s Hashbang boom.
One of the problems with this debate is that many people weighing in are setting up a dubious dichotomy between “pragmatism” (we must use hashbang to serve our users) and “correctness” (we must not use hashbang to avoid breaking things). Reading some of the posts and comments it struck me that a fair number of people were jumping in with their opinions without taking the time to really understand the other side; in particular there are a fair number of glib justifications of both positions that are, sadly, short on facts. As Ben Ward said when he weighed in on this issue:
Misleading errors and tangents in vitriolic argument really don't help anything, and distract us from making a clearly robust case and documenting the facts of a risky methodology.
And there are a lot of facts. It’s taken me a week to get to the point of writing this, the first in what I suspect will become four or five different articles. Part of the problem is that there is a lot going on in a complete web stack these days, from various Javascript APIs in the browsers, down through URIs and HTTP to the bits, packets and so on that make up the internet. Almost no one can hope to properly grasp all the aspects of this in their day to day work (although we must try, an issue I plan to get to around volume 6 ;-). Hence, I’ve been reading, researching and testing like crazy in what little time I’ve had outside my day job.
Pretty much everything I’ve uncovered will be known by some or even many people; some of it is even well-discussed on the internet already. Hopefully by bringing it all together I can provide a little structure around some of the things we have to contend with when building modern websites and web apps. I’ve tried to assume as little knowledge as possible; this is a series of articles rather than a blog post, so if the earlier commentary seemed too distinct from your experience and the problems you face, perhaps this will be more accessible.
tl;dr
I’m trying here to present the facts objectively and to explain why this is a difficult issue. However I have my own opinions, which will come out across the course of this series. Not everyone is going to want to wade through the whole article (let alone a number of them) though, so here’s the bullet.
- hashbangs are bad
- hashbangs are necessary sometimes, right now
- hashbangs will be with us longer than we want
- hashbangs aren’t needed as often as some people think; there’s a happy medium to be found
That last is going to take some getting to; in this article I lay out the foundation, but I can’t demonstrate where I feel that happy medium lies nearly so quickly. To do that properly is going to take time, and if we’re going to do that, let’s start at the beginning. How do web apps different from websites; and how do they differ from other apps?
Websites and web apps
web site - A collection of HTML and subordinate documents on the World Wide Web that are typically accessible from the same URL and residing on the same server, and form a coherent, usually interlinked whole
In software engineering, a web application is an application that is accessed via a web browser over a network such as the Internet or an intranet
An application is "computer software designed to help the user to perform singular or multiple related specific tasks"
When we talk about a web app, what we mean is an application, something you use to do something or another (write a presentation, chat online or whatever), which you use via a web browser. Up comes the web browser, you point it at the web app, and away you go. Everything beyond that is irrelevant; you can have a web app which doesn’t use the network beyond delivering the app in the first place. Most will use the network once they’re running, to save state, to communicate information between different users, and so on; and most of what we’re talking about here really only applies to those that do.
Ben Cherry, a Twitter developer, discusses this a little in his own take on hashbang, where he makes the argument that what we’re seeing is just a natural result of the rise of the web app. I agree with this, but I disagree with some of the other things he says, in particular:
Web domains are now serving desktop-class applications via HTTP
[Twitter] is simply an application that you happen to launch by pointing a browser at http://twitter.com
I think the two of these together miss the two fundamental differences between web apps and more traditional desktop or mobile applications, even when all of them use the network for fetching data and providing communications layers with other users:
- you don’t install a web app; you just navigate to it and it becomes available
- the browser environment is impoverished compared to other substrates; web apps are not (yet) “desktop-class”
- web apps are part of the web, and hence may be made linkable
Note that the last point says may be made linkable; there’s no requirement. However it is the most important; in my opinion this is the single thing that makes web apps significantly more powerful than traditional desktop apps.
Cherry notes that URLs bring benefits like bookmarks […]
, before sadly leaving the topic to talk about other things. His arguments in favour of using hashbangs are pretty robust, but that linkability is really what’s bugging everyone who’s against them, and I haven’t found a completely cogent argument that it’s irrelevant. The best is a kind of pragmatism line: since hashbangs work in the majority of web browsers, and Google has provided a way for web crawlers to get the content, and since this will all go away once the draft HTML5 History API is widely supported, we shouldn’t worry too much. But people clearly are worrying, so we should try to figure out why.
At the heart of this is a tension between supporting deep linking while providing the increased functionality that web apps allow. Some people also raise an argument about performance, which I’ll get to much later in this series.
Deep linking: the people are upset
"Deep linking" is a phrase that was familiar a few years ago for a series of court cases where some publishers tried to prevent other sites from directly linking (deep linking) to the juicy content, enabling users to bypass whatever navigation or site flow the original publishers had in place. As the Wikipedia article points out, the web’s fundamental protocol, HTTP, makes no distinction between deep links or any other kind; from a traditional HTTP point of view a URI points to a resource, and user agents know how to dereference (look up) this to get hold of a copy of that resource (technically, it’s called a resource representation).
Note that I say “user agents” rather than “web browsers” (I’ll often call them web clients from now on, in comparison to web servers). We’ll come back to that later.
Changing fragments
The problem with hashbangs and deep linking is that they require user agents to understand more than basic HTTP. The hashbang works by giving meaning to a specific part of a link called the fragment identifier; the bit after the # character. Fragment identifiers are defined in section 3.5 of RFC 3986, although the details don’t really matter. What’s important is that the fragment and the rest of the URI are handled separately: the “main” part of the URI is sent to the web server, but the fragment is handled only by the web client. In RFC 3986’s somewhat dry language:
the identifying information within the fragment itself is dereferenced solely by the user agent
This is all fine the way they were originally used with HTML; fragment identifiers typically map to “anchors” within the HTML, such as the one defined using the <a> tag in the following snippet:
<dt><a name="adef-name-A"><samp>name</samp></a> = <em>cdata</em> [CS]</dt>
<dd>This attribute names the current anchor so that it may be the destination
of another link. The value of this attribute must be a unique anchor name. The
scope of this name is the current document. Note that this attribute shares the
same name space as the <samp>id</samp> attribute.</dd>
(sanitised from the HTML 4.01 spec marked up as HTML)
With that HTML fragment as part of http://www.w3.org/TR/html401/struct/links.html, anyone else could link to http://www.w3.org/TR/html401/struct/links.html#adef-name-A and any web client could download from the URI (without the fragment), and find the relevant bit of text within it (by looking for the fragment inside the HTML). This is what Tim Bray is talking about in the first example in How It Works (see the fragment coming into play?).
What’s happened since then is that people have come up with a new use of fragments; instead of marking places within the resource representation (in this case, the HTML), they are hints to Javascript running in the web client as to what they should display. In the case of twitter, this often involves the Javascript looking at the fragment and then loading something else from twitter’s API; the information you’re looking for is often not in the HTML in the first place.
The reason they do this is that changing the fragment doesn’t change the page you’re on; you can change the fragment from Javascript and web clients won’t load a different page. This means that as you navigate through content in your web app, you can change the fragment to match the content you’re looking at — so people can copy that link as a bookmark or send to other people. When you go back to that link later, the Javascript on the page can check the fragment and figure out what content to load and display.
This changes the meaning of a fragment from content to be located in the page to content to be loaded into the page. The fragment is now providing information for what is termed client-side routing, by analogy with the normal server-side job of figuring out what content is desired for a particular URI, termed routing in many systems such as ASP.NET and Ruby on Rails.
The problem
Simply put, if you aren’t running the page’s Javascript, then a URI designed for client-side routing doesn’t lead you to the intended content. There are various reasons why this might bite you, and the most visible reason is if you’re Google.
An interim solution
Hashbang is a system introduced by Google to try to mitigate the pain of client-side routing described above, specifically that it makes it difficult or impossible for search engines to index such systems (which for historical and utterly confusing reasons are sometimes referred to as AJAX applications). Hashbangs are an ad-hoc standard that allows web crawlers working for Google, Bing or whoever, to convert a URI with a hashbang into a URI without a hashbang, at which point they can behave as if the client-side routing weren’t there and grab the content they need.
It’s worth pointing out that this is strictly a short-term hack; there’s a nascent proposal called the History API that I mentioned earlier which would allow the same Javascript systems that are doing client-side routing to change the entire URI rather than just the fragment. Then you get all the advantages of web apps and client-side routing without the disadvantages. However we’re not there yet: the history API is only a draft, and probably won’t be implemented in Internet Explorer for some time yet. (Some people are railing against that, saying that it — and a number of other omissions — mean IE isn’t a modern browser in some sense; I really don’t want to get dragged into yet another tar pit argument, but it seems to me that Microsoft is actually being utterly sane in focussing on what they see as the most important challenges web browsers need to address; we can argue with their priorities, but it’s difficult to complain as we used to that they are sitting there doing nothing and letting IE stagnate.)
Creating a middle class
However in the meantime it means we’re moving down a slope of ghettoising web clients (or user agents as the specifications tend to call them). In the beginning, we had just one class of web client:
| Content | All web clients |
|---|
| Everything | Full access |
Then we got client-side routing, and we had two classes:
| Content | Javascript support | No Javascript support |
|---|
| Server-side routing | Full access | Full access |
| Client-side routing | Full access | No access |
With hashbangs, we’ve created a middle class:
| Content | Javascript support | Hashbang understanding but no Javascript support | No Javascript support |
|---|
| Server-side routing | Full access | Full access | Full access |
| Client-side routing using hashbangs | Full access | Full or partial access | No access |
| Client-side routing without hashbangs | Full access | No access | No access |
Note that Twitter’s approach to solve the “no access” case involves having another way of accessing their system without using Javascript. This almost but not quite closes the gap, and the kicker is once more deep linking.
Inside the hashbang ghetto
At first glance, there’s not much in the ghetto: web crawlers that haven’t updated to use hashbangs, and older web browsers that don’t support Javascript. It’s actually a bit more complex than that, but if you weigh up the costs of implementing things without hashbangs and decide it isn’t worth it to support the ghetto, that’s entirely your business. If it turns out you’re wrong, your web app will die, and it’ll be your fault; on the other hand, if you’re right you may have made it easier to provide the richer functionality that can set you apart from the rest of the herd and make your web app a huge success. Twitter have decided that the downside for them is sufficiently small to take the risk; and they’re probably right. But I’m not going to stop here, because this is where things start getting really interesting. The ghetto isn’t just dead browsers and antiquated search engines.
Here’s a slide from a talk I gave about three years ago.
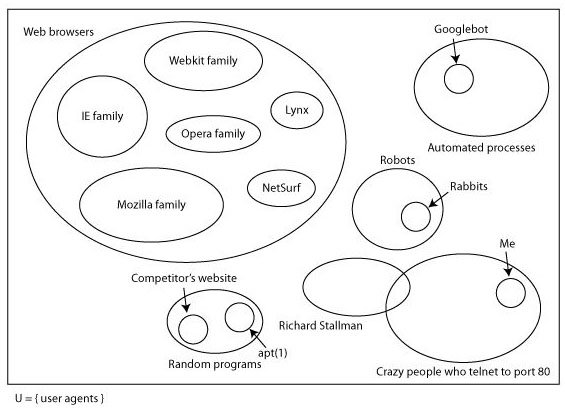
This is why I try not to talk about web browsers: there’s a huge space of other things that can talk HTTP. Some of them aren’t terribly important to web apps (robots like Nabaztag probably aren’t going to be reading twitter through their web app), and some of the concerns I was talking about (botnets and rent-a-hackers that competitors might hire to take down your site) don’t really mind whether you’re using hashbangs or not. But there are useful tools that, for instance, might scan links in your email and use them to categorise or flag things that are important to you. Chances are that they won’t implement hashbangs ever (some of them may no longer be maintained, although they’ll work perfectly well except in this case), in which case good luck having them work properly with any web app that does.
The problem here is that although it’s possible to be reasonably careful about user agents that hit your site from the beginning, by redirecting them to a non-Javascript version of the site for instance, this falls down when people are deep linking and sharing those links around. Let’s look at what actually happens to a ghetto user agent when it tries to dereference a Twitter hashbang URI. We’ll use this tweet from Dustin Diaz because it has a pretty map in it.
The URI is http://twitter.com/#!/ded/status/18308450276, so any user agent (except for crawlers using Google’s hashbang algorithm) will first request http://twitter.com/ and then apply the fragment. There are two possible responses from Twitter depending on whether you have an active #newtwitter session (ie whether you’re logged into an account that’s using newtwitter or not).
With newtwitter enabled, you get about 70K of HTML with embedded Javascript. Dustin’s tweet is nowhere to be found; it will be loaded by the Javascript. Without newtwitter, you get about 50K of HTML and Javascript; Dustin’s tweet is also nowhere to be found, but the first thing the Javascript does is to redirect to http://twitter.com/ded/status/18308450276, which gives you the tweet in about 13K of HTML and Javascript.
Any tool that wants to find out the contents of the tweet is going to have to either:
- understand hashbangs
- run some Javascript
- embed a full-featured web browser that runs Javascript
That’s a big step up from the days when we only had one class of web client, and that’s really what people on the correctness side of the argument are getting upset about. There are no end of tools already in existence that can speak HTTP but can’t cope with hashbangs; if you use client-side routing, these tools aren’t going to work with your web app.
You may decide this doesn’t matter, of course, but the ghetto is full of these tools, and I can guarantee you neither know about all of them, nor appreciate how some people are depending on them for their full appreciation of the web. (In that slide above, there’s a section for crazy people who telnet to port 80, something I do sometimes to try to figure out whether I can’t open your site because of problems with your web server, problems with my internet connection or, as seems to be increasingly the case, because Safari has gone mental for a bit and is just refusing to load anything. This is one of the least crazy non-standard uses of HTTP I can think of.)
It’s easy to fixate on the most obvious aspect of ghetto browsers: things that don’t understand Javascript. Many people have put a lot of effort over the past several years into the various arguments why having a site that works without Javascript is a good idea, but in the case of web apps people are ignoring all that because at first blush web apps don’t apply if you don’t have Javascript. Certainly a complex web app isn’t going to run without Javascript; however I think this is missing the point. Going back to the fundamental distinguishing feature of a web app, deep links can escape from the web app itself to float around the internet; I’d say this is an unambiguously good thing. But, as I think should be obvious by now, the deep linking problem has nothing to do with whether your web browser supports Javascript (or has it turned on); it’s really to do with the shift in meaning of fragments that Tim Bray complained about. These days there is meaning in them that can’t be divined by reading the HTML specification.
For instance, Facebook do a neat trick when you paste links into a Facebook message: they look at the page and pull out interesting information. They sometimes do this using the Open Graph protocol, which is rooted in spreading deep links around between different systems and having them pull data out of the resource representations at the end of them; sometimes they look for other hints. Part of the point of the Open Graph is that it’s not just Facebook who can pull stuff out of it; anyone can. There are libraries available, and when I checked recently none of them could cope with hashbangs. (It’s some small comfort that Facebook themselves have put hashbang support into their Open Graph consumption.)
I was discussing hashbangs last week with George Brocklehurst when he said:
Whenever I copy a twitter URI I have to remember to remove the hashbang.
All George is trying to do is ensure that URIs he’s moving around are as useful as possible; that he feels he needs to strip the hashbang suggests a deep problem.
The safe solution
For the time being, the safest approach is to limit client-side routing to parts of your web app that don’t make sense outside the app. Considering twitter, there are some things that you naturally want to link to:
- user profiles
- tweets
- user lists
and then there are parts of the app that don’t really make sense for anyone other than you, right now:
- your current main dashboard (latest tweets from your followers, local trends, suggestions of who to follow and so forth)
- live search results
and so on. Actually, even the latter ones tend to get separate (albeit hashbanged) URLs in Twitter; but since the first ones are the ones you are most likely to copy into an email, or Facebook, or heaven forbid back into Twitter, those are the ones that are most important.
Twitter handles this at the moment by changing the fragment and loading the information for that view in Javascript. The safe way of doing it is to do a page load on these “core objects” so that they have non-hashbanged URIs. (The HTML served in these cases could still load the Javascript for the Twitter app, most of which is cached and served from Akamai anyway.) For the reasons not to use the safe approach, we have to venture away from deep linking and into the other desire that web app builders have which, by analogy, we’ll call deep functionality; from there we’ll move on to look at performance, which will turn out to be a much more complex subject than it appears (or at least than it initially appeared to me when I started thinking about this, back when I thought it could be a single article).
But that’s all for the future. I’m well aware that by stopping at this point I’m leaving myself open to abuse because I’ve only addressed one side of the argument. Trust me, the other side is coming; please don’t clutter the internet with vitriol in the meantime.
- Published at
- Sunday 7th February, 2010
- Tagged as
Note that the extension this talks about has subsequently been renamed to django_exceptional_middleware.
Django has support for emitting a response with any HTTP status code. However some of these are exceptional conditions, so the natural Pythonic way of generating them would be by throwing a suitable exception. However except for two very common situations (in which you get default template rendering unless you’re prepared to do a bit of work), Django doesn’t make this an easy approach.
At the third /dev/fort we needed something to make this easy, which Richard Boulton threw together and I subsequently turned into a Django app. It allows you to override the way that exceptional status codes are rendered.
Usual HTTP status codes in Django
In Django, HTTP responses are built up as an object, and one of the things you can set is the HTTP status code, a number that tells your user agent (web browser, indexing spider, Richard Stallman’s email gateway) what to do with the rest of the response. Django has some convenient built-in support for various common status codes.
The default is 200 OK, which usually means “here’s your web page, all is well” (or “here’s your image” or whatever). This is the code that you get automatically when a Django view function spits out a response, often by rendering a template.
Another thing you often want to do is to issue a redirect, most commonly 301 Moved Permanently or 302 Found. For instance, you do this if you have an HTML <form> that POSTs some data, and then you want to direct the web browser (indexing spider, RMS’s gateway) to another page once you’ve done whatever updating action is represented by the POST data.
404 Not Found, which is usually the correct response when the URI doesn’t refer to anything within your system. Django handles this automatically if the URI doesn’t match anything in your Django project’s URLconf, and it’ll also emit it if you raise an Http404 exception in a view.
500 Internal Server Error, which Django uses if something goes wrong in your code, or say if your database is down and you haven’t catered for that.
For 200, your code is in control of the HTTP response entity, which is generally the thing displayed in a web browser, parsed by an indexing spider, or turning up in an email. For 301 and 302, the entity is ignored in many cases, although it can contain say a web page explaining the redirect.
For 404 and 500, the default Django behaviour is to render the templates 404.html and 500.html respectively; you can change the function that does this, which allows you to set your own RenderContext appropriately (so that you can inject some variables common across all your pages, for instance). Usually I make this use my project-wide render convenience function, which sets up various things in the context that are used on every page. (You could also add something to TEMPLATE_CONTEXT_PROCESSORS to manage this, but that’s slightly less powerful since you’re still accepting a normal template render in that case.)
I want a Pony!
Okay, so I had two problems with this. Firstly, I got thoroughly fed up of copying my handler404 and handler500 functions around and remembering to hook them up. Secondly, for the /dev/fort project we needed to emit 403 Forbidden regularly, and wanted to style it nicely. 403 is clearly an exceptional response, so it should be generated by raising an exception of some sort in the relevant view function. The alternative is some frankly revolting code:
def view(request, slug):
obj = get_object_by_slug(slug)
if not request_allowed_to_see_object(request, obj):
return HttpResponseForbidden(...)
Urgh. What I want to do is this:
def view_request, slug):
obj = get_object_or_403(MyModel, slug=slug)
which will then raise a (new) Http403 exception automatically if there isn’t a matching object. Then I want the exception to trigger a nice rendered template configured elsewhere in the project.
This little unicorn went “501, 501, 501” all the way home
If you don’t care about 403, then maybe you just want to use HTTP status codes as easter eggs, in the way that Wildlife Near You does; some of its species are noted as 501 Not Implemented (in this universe).
get_object_or_403 (a disgression)
If you’ve used Django a bit you’ll have encountered the convenience function get_object_or_404, which looks up a model instance based on parameters to the function, and raises Http404 for you if there’s no matching instance. get_object_or_403 does exactly the same, but raises a different exception. Combine this with some middleware (which I’ll describe in a minute) and everything works as I want. The only question is: why would I want to raise a 403 when an object isn’t found? Surely that’s what 404 is for?
The answer is: privacy, and more generally: preventing unwanted information disclosure. Say you have a site which allows users (with URLs such as /user/james) to show support for certain causes. For each cause, there’s a given slug, so “vegetarianism” has the slug vegetarianism and so on; the page about that user’s support of vegetarianism would then be /user/james/vegetarianism. Someone’s support of a cause may be public (anyone can see it) or private (only people they specifically approve can see it). This leads to three possible options for each cause, and the “usual” way of representing these using HTTP status codes would be as follows:
- the user supports it publicly, and
/user/james/vegetarianism returns 200
- the user supports it privately, and
/user/james/vegetarianism returns 403 (unless you’re on the list, in which case you get 200 as above)
- the user doesn’t support the cause, and
/user/james/vegetarianism returns 404
This is fine when the main point is to hide the details of the user’s support. However if the cause is “international fascism” (international-fascism), a user supporting privately may not want the fact that they support the cause to be leaked to the general public at all. At this point, either the site should always return 404 to mean “does not support or you aren’t allowed to know”, or the site should always return 403 to mean the same thing.
The HTTP specification actually suggests (weakly) using 404 where you don’t want to admit the reason for denying access, but either way is apparently fine by the book, and in some cases 403 is going to make more sense than 404. However since Django doesn’t give any magic support for raising an exception that means 403, we needed an exception and some middleware to catch it and turn it into a suitable response.
django_custom_rare_http_responses
The idea then is that you raise exceptions that are subclasses of django_custom_rare_http_responses.responses.RareHttpResponse (some of the more useful ones are in django_custom_rare_http_responses.responses), and the middleware will then render this using a template http_responses/404.html or whatever. If that template doesn’t exist, it’ll use http_responses/default.html, and if that doesn’t exist, the app has its own default (make sure that you have django.template.loaders.app_directories.load_template_source in your TEMPLATE_LOADERS setting if you want to rely on this).
In order to override the way that the template is rendered, you want to call django_custom_rare_http_responses.middleware.set_renderer with a callable that takes a request object, a template name and a context dictionary, the last of which is set up with http_code, http_message (in English, taken from django.core.handlers.wsgi.STATUS_CODE_TEXT) and http_response_exception (allowing you to subclass RareHttpResponse yourself to pass through more information if you need). The default just calls the render_to_response shortcut in the expected way.
What this means in practice is that you can add django_custom_rare_http_responses.middleware.CustomRareHttpResponses to MIDDLEWARE_CLASSES, and django_custom_rare_http_responses to INSTALLED_APPS, than raise HttpForbidden (for 403), HttpNotImplemented (for 501) and so on. All you need to do to prettify them is to create a template http_responses/default.html and away you go.
My Pony only has three legs
This isn’t finished. Firstly, those 500 responses that Django generates because of other exceptions raised by your code aren’t being handled by this app. Secondly, and perhaps more importantly, adding this app currently changes the behaviour of Django in an unexpected fashion. Without it, and when settings.DEBUG is True, 404s are reported as a helpful backtrace; with it, these are suddenly rendered using your pretty template, which is a little unexpected.
However these are both fairly easy to fix; if it bugs you and I haven’t got round to it, send me a pull request on github once you’re done.