The latest flurry of doom-saying to hit the web is over the use (and particularly twitter’s use, although they’re not alone by any means) of “hashbangs”. This just means URI fragment identifiers that start with ! (so the URI displayed in the browser contains #!), and then using Javascript to figure out what to load on top of the basic HTML to give the desired content.
Twitter have been doing this since they rolled out #newtwitter, their application-like refresh of their website back in September of last year; the root of this sudden interest seems to be Mike Davies’ Breaking the Web with hash-bangs, with the negative side picked up by people as diverse as Jeremy Keith in the charmingly-titled Going Postel and Tim Bray with Broken Links. The flip side, supporting the use of hashbang (although generally with caveats, since pretty much everyone agrees they should be a temporary hack only) is also widespread, with one of the most straightforward rebuttals being Tom Gibara’s Hashbang boom.
One of the problems with this debate is that many people weighing in are setting up a dubious dichotomy between “pragmatism” (we must use hashbang to serve our users) and “correctness” (we must not use hashbang to avoid breaking things). Reading some of the posts and comments it struck me that a fair number of people were jumping in with their opinions without taking the time to really understand the other side; in particular there are a fair number of glib justifications of both positions that are, sadly, short on facts. As Ben Ward said when he weighed in on this issue:
Misleading errors and tangents in vitriolic argument really don't help anything, and distract us from making a clearly robust case and documenting the facts of a risky methodology.
And there are a lot of facts. It’s taken me a week to get to the point of writing this, the first in what I suspect will become four or five different articles. Part of the problem is that there is a lot going on in a complete web stack these days, from various Javascript APIs in the browsers, down through URIs and HTTP to the bits, packets and so on that make up the internet. Almost no one can hope to properly grasp all the aspects of this in their day to day work (although we must try, an issue I plan to get to around volume 6 ;-). Hence, I’ve been reading, researching and testing like crazy in what little time I’ve had outside my day job.
Pretty much everything I’ve uncovered will be known by some or even many people; some of it is even well-discussed on the internet already. Hopefully by bringing it all together I can provide a little structure around some of the things we have to contend with when building modern websites and web apps. I’ve tried to assume as little knowledge as possible; this is a series of articles rather than a blog post, so if the earlier commentary seemed too distinct from your experience and the problems you face, perhaps this will be more accessible.
tl;dr
I’m trying here to present the facts objectively and to explain why this is a difficult issue. However I have my own opinions, which will come out across the course of this series. Not everyone is going to want to wade through the whole article (let alone a number of them) though, so here’s the bullet.
- hashbangs are bad
- hashbangs are necessary sometimes, right now
- hashbangs will be with us longer than we want
- hashbangs aren’t needed as often as some people think; there’s a happy medium to be found
That last is going to take some getting to; in this article I lay out the foundation, but I can’t demonstrate where I feel that happy medium lies nearly so quickly. To do that properly is going to take time, and if we’re going to do that, let’s start at the beginning. How do web apps different from websites; and how do they differ from other apps?
Websites and web apps
web site - A collection of HTML and subordinate documents on the World Wide Web that are typically accessible from the same URL and residing on the same server, and form a coherent, usually interlinked whole
In software engineering, a web application is an application that is accessed via a web browser over a network such as the Internet or an intranet
An application is "computer software designed to help the user to perform singular or multiple related specific tasks"
When we talk about a web app, what we mean is an application, something you use to do something or another (write a presentation, chat online or whatever), which you use via a web browser. Up comes the web browser, you point it at the web app, and away you go. Everything beyond that is irrelevant; you can have a web app which doesn’t use the network beyond delivering the app in the first place. Most will use the network once they’re running, to save state, to communicate information between different users, and so on; and most of what we’re talking about here really only applies to those that do.
Ben Cherry, a Twitter developer, discusses this a little in his own take on hashbang, where he makes the argument that what we’re seeing is just a natural result of the rise of the web app. I agree with this, but I disagree with some of the other things he says, in particular:
Web domains are now serving desktop-class applications via HTTP
[Twitter] is simply an application that you happen to launch by pointing a browser at http://twitter.com
I think the two of these together miss the two fundamental differences between web apps and more traditional desktop or mobile applications, even when all of them use the network for fetching data and providing communications layers with other users:
- you don’t install a web app; you just navigate to it and it becomes available
- the browser environment is impoverished compared to other substrates; web apps are not (yet) “desktop-class”
- web apps are part of the web, and hence may be made linkable
Note that the last point says may be made linkable; there’s no requirement. However it is the most important; in my opinion this is the single thing that makes web apps significantly more powerful than traditional desktop apps.
Cherry notes that URLs bring benefits like bookmarks […]
, before sadly leaving the topic to talk about other things. His arguments in favour of using hashbangs are pretty robust, but that linkability is really what’s bugging everyone who’s against them, and I haven’t found a completely cogent argument that it’s irrelevant. The best is a kind of pragmatism line: since hashbangs work in the majority of web browsers, and Google has provided a way for web crawlers to get the content, and since this will all go away once the draft HTML5 History API is widely supported, we shouldn’t worry too much. But people clearly are worrying, so we should try to figure out why.
At the heart of this is a tension between supporting deep linking while providing the increased functionality that web apps allow. Some people also raise an argument about performance, which I’ll get to much later in this series.
Deep linking: the people are upset
"Deep linking" is a phrase that was familiar a few years ago for a series of court cases where some publishers tried to prevent other sites from directly linking (deep linking) to the juicy content, enabling users to bypass whatever navigation or site flow the original publishers had in place. As the Wikipedia article points out, the web’s fundamental protocol, HTTP, makes no distinction between deep links or any other kind; from a traditional HTTP point of view a URI points to a resource, and user agents know how to dereference (look up) this to get hold of a copy of that resource (technically, it’s called a resource representation).
Note that I say “user agents” rather than “web browsers” (I’ll often call them web clients from now on, in comparison to web servers). We’ll come back to that later.
Changing fragments
The problem with hashbangs and deep linking is that they require user agents to understand more than basic HTTP. The hashbang works by giving meaning to a specific part of a link called the fragment identifier; the bit after the # character. Fragment identifiers are defined in section 3.5 of RFC 3986, although the details don’t really matter. What’s important is that the fragment and the rest of the URI are handled separately: the “main” part of the URI is sent to the web server, but the fragment is handled only by the web client. In RFC 3986’s somewhat dry language:
the identifying information within the fragment itself is dereferenced solely by the user agent
This is all fine the way they were originally used with HTML; fragment identifiers typically map to “anchors” within the HTML, such as the one defined using the <a> tag in the following snippet:
<dt><a name="adef-name-A"><samp>name</samp></a> = <em>cdata</em> [CS]</dt>
<dd>This attribute names the current anchor so that it may be the destination
of another link. The value of this attribute must be a unique anchor name. The
scope of this name is the current document. Note that this attribute shares the
same name space as the <samp>id</samp> attribute.</dd>
(sanitised from the HTML 4.01 spec marked up as HTML)
With that HTML fragment as part of http://www.w3.org/TR/html401/struct/links.html, anyone else could link to http://www.w3.org/TR/html401/struct/links.html#adef-name-A and any web client could download from the URI (without the fragment), and find the relevant bit of text within it (by looking for the fragment inside the HTML). This is what Tim Bray is talking about in the first example in How It Works (see the fragment coming into play?).
What’s happened since then is that people have come up with a new use of fragments; instead of marking places within the resource representation (in this case, the HTML), they are hints to Javascript running in the web client as to what they should display. In the case of twitter, this often involves the Javascript looking at the fragment and then loading something else from twitter’s API; the information you’re looking for is often not in the HTML in the first place.
The reason they do this is that changing the fragment doesn’t change the page you’re on; you can change the fragment from Javascript and web clients won’t load a different page. This means that as you navigate through content in your web app, you can change the fragment to match the content you’re looking at — so people can copy that link as a bookmark or send to other people. When you go back to that link later, the Javascript on the page can check the fragment and figure out what content to load and display.
This changes the meaning of a fragment from content to be located in the page to content to be loaded into the page. The fragment is now providing information for what is termed client-side routing, by analogy with the normal server-side job of figuring out what content is desired for a particular URI, termed routing in many systems such as ASP.NET and Ruby on Rails.
The problem
Simply put, if you aren’t running the page’s Javascript, then a URI designed for client-side routing doesn’t lead you to the intended content. There are various reasons why this might bite you, and the most visible reason is if you’re Google.
An interim solution
Hashbang is a system introduced by Google to try to mitigate the pain of client-side routing described above, specifically that it makes it difficult or impossible for search engines to index such systems (which for historical and utterly confusing reasons are sometimes referred to as AJAX applications). Hashbangs are an ad-hoc standard that allows web crawlers working for Google, Bing or whoever, to convert a URI with a hashbang into a URI without a hashbang, at which point they can behave as if the client-side routing weren’t there and grab the content they need.
It’s worth pointing out that this is strictly a short-term hack; there’s a nascent proposal called the History API that I mentioned earlier which would allow the same Javascript systems that are doing client-side routing to change the entire URI rather than just the fragment. Then you get all the advantages of web apps and client-side routing without the disadvantages. However we’re not there yet: the history API is only a draft, and probably won’t be implemented in Internet Explorer for some time yet. (Some people are railing against that, saying that it — and a number of other omissions — mean IE isn’t a modern browser in some sense; I really don’t want to get dragged into yet another tar pit argument, but it seems to me that Microsoft is actually being utterly sane in focussing on what they see as the most important challenges web browsers need to address; we can argue with their priorities, but it’s difficult to complain as we used to that they are sitting there doing nothing and letting IE stagnate.)
Creating a middle class
However in the meantime it means we’re moving down a slope of ghettoising web clients (or user agents as the specifications tend to call them). In the beginning, we had just one class of web client:
| Content | All web clients |
|---|---|
| Everything | Full access |
Then we got client-side routing, and we had two classes:
| Content | Javascript support | No Javascript support |
|---|---|---|
| Server-side routing | Full access | Full access |
| Client-side routing | Full access | No access |
With hashbangs, we’ve created a middle class:
| Content | Javascript support | Hashbang understanding but no Javascript support | No Javascript support |
|---|---|---|---|
| Server-side routing | Full access | Full access | Full access |
| Client-side routing using hashbangs | Full access | Full or partial access | No access |
| Client-side routing without hashbangs | Full access | No access | No access |
Note that Twitter’s approach to solve the “no access” case involves having another way of accessing their system without using Javascript. This almost but not quite closes the gap, and the kicker is once more deep linking.
Inside the hashbang ghetto
At first glance, there’s not much in the ghetto: web crawlers that haven’t updated to use hashbangs, and older web browsers that don’t support Javascript. It’s actually a bit more complex than that, but if you weigh up the costs of implementing things without hashbangs and decide it isn’t worth it to support the ghetto, that’s entirely your business. If it turns out you’re wrong, your web app will die, and it’ll be your fault; on the other hand, if you’re right you may have made it easier to provide the richer functionality that can set you apart from the rest of the herd and make your web app a huge success. Twitter have decided that the downside for them is sufficiently small to take the risk; and they’re probably right. But I’m not going to stop here, because this is where things start getting really interesting. The ghetto isn’t just dead browsers and antiquated search engines.
Here’s a slide from a talk I gave about three years ago.
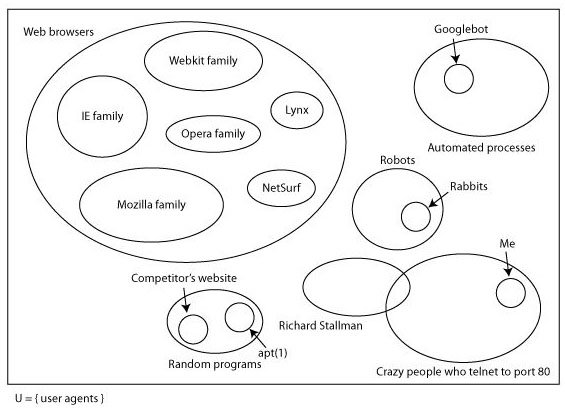
This is why I try not to talk about web browsers: there’s a huge space of other things that can talk HTTP. Some of them aren’t terribly important to web apps (robots like Nabaztag probably aren’t going to be reading twitter through their web app), and some of the concerns I was talking about (botnets and rent-a-hackers that competitors might hire to take down your site) don’t really mind whether you’re using hashbangs or not. But there are useful tools that, for instance, might scan links in your email and use them to categorise or flag things that are important to you. Chances are that they won’t implement hashbangs ever (some of them may no longer be maintained, although they’ll work perfectly well except in this case), in which case good luck having them work properly with any web app that does.
The problem here is that although it’s possible to be reasonably careful about user agents that hit your site from the beginning, by redirecting them to a non-Javascript version of the site for instance, this falls down when people are deep linking and sharing those links around. Let’s look at what actually happens to a ghetto user agent when it tries to dereference a Twitter hashbang URI. We’ll use this tweet from Dustin Diaz because it has a pretty map in it.
The URI is http://twitter.com/#!/ded/status/18308450276, so any user agent (except for crawlers using Google’s hashbang algorithm) will first request http://twitter.com/ and then apply the fragment. There are two possible responses from Twitter depending on whether you have an active #newtwitter session (ie whether you’re logged into an account that’s using newtwitter or not).
With newtwitter enabled, you get about 70K of HTML with embedded Javascript. Dustin’s tweet is nowhere to be found; it will be loaded by the Javascript. Without newtwitter, you get about 50K of HTML and Javascript; Dustin’s tweet is also nowhere to be found, but the first thing the Javascript does is to redirect to http://twitter.com/ded/status/18308450276, which gives you the tweet in about 13K of HTML and Javascript.
Any tool that wants to find out the contents of the tweet is going to have to either:
- understand hashbangs
- run some Javascript
- embed a full-featured web browser that runs Javascript
That’s a big step up from the days when we only had one class of web client, and that’s really what people on the correctness side of the argument are getting upset about. There are no end of tools already in existence that can speak HTTP but can’t cope with hashbangs; if you use client-side routing, these tools aren’t going to work with your web app.
You may decide this doesn’t matter, of course, but the ghetto is full of these tools, and I can guarantee you neither know about all of them, nor appreciate how some people are depending on them for their full appreciation of the web. (In that slide above, there’s a section for crazy people who telnet to port 80, something I do sometimes to try to figure out whether I can’t open your site because of problems with your web server, problems with my internet connection or, as seems to be increasingly the case, because Safari has gone mental for a bit and is just refusing to load anything. This is one of the least crazy non-standard uses of HTTP I can think of.)
It’s easy to fixate on the most obvious aspect of ghetto browsers: things that don’t understand Javascript. Many people have put a lot of effort over the past several years into the various arguments why having a site that works without Javascript is a good idea, but in the case of web apps people are ignoring all that because at first blush web apps don’t apply if you don’t have Javascript. Certainly a complex web app isn’t going to run without Javascript; however I think this is missing the point. Going back to the fundamental distinguishing feature of a web app, deep links can escape from the web app itself to float around the internet; I’d say this is an unambiguously good thing. But, as I think should be obvious by now, the deep linking problem has nothing to do with whether your web browser supports Javascript (or has it turned on); it’s really to do with the shift in meaning of fragments that Tim Bray complained about. These days there is meaning in them that can’t be divined by reading the HTML specification.
For instance, Facebook do a neat trick when you paste links into a Facebook message: they look at the page and pull out interesting information. They sometimes do this using the Open Graph protocol, which is rooted in spreading deep links around between different systems and having them pull data out of the resource representations at the end of them; sometimes they look for other hints. Part of the point of the Open Graph is that it’s not just Facebook who can pull stuff out of it; anyone can. There are libraries available, and when I checked recently none of them could cope with hashbangs. (It’s some small comfort that Facebook themselves have put hashbang support into their Open Graph consumption.)
I was discussing hashbangs last week with George Brocklehurst when he said:
Whenever I copy a twitter URI I have to remember to remove the hashbang.
All George is trying to do is ensure that URIs he’s moving around are as useful as possible; that he feels he needs to strip the hashbang suggests a deep problem.
The safe solution
For the time being, the safest approach is to limit client-side routing to parts of your web app that don’t make sense outside the app. Considering twitter, there are some things that you naturally want to link to:
- user profiles
- tweets
- user lists
and then there are parts of the app that don’t really make sense for anyone other than you, right now:
- your current main dashboard (latest tweets from your followers, local trends, suggestions of who to follow and so forth)
- live search results
and so on. Actually, even the latter ones tend to get separate (albeit hashbanged) URLs in Twitter; but since the first ones are the ones you are most likely to copy into an email, or Facebook, or heaven forbid back into Twitter, those are the ones that are most important.
Twitter handles this at the moment by changing the fragment and loading the information for that view in Javascript. The safe way of doing it is to do a page load on these “core objects” so that they have non-hashbanged URIs. (The HTML served in these cases could still load the Javascript for the Twitter app, most of which is cached and served from Akamai anyway.) For the reasons not to use the safe approach, we have to venture away from deep linking and into the other desire that web app builders have which, by analogy, we’ll call deep functionality; from there we’ll move on to look at performance, which will turn out to be a much more complex subject than it appears (or at least than it initially appeared to me when I started thinking about this, back when I thought it could be a single article).
But that’s all for the future. I’m well aware that by stopping at this point I’m leaving myself open to abuse because I’ve only addressed one side of the argument. Trust me, the other side is coming; please don’t clutter the internet with vitriol in the meantime.