When I wrote about hashbangs, deep linking and ghettoised browsers, I genuinely thought I’d be able to punch out the second article within a couple of weeks. I failed utterly, due to a combination of illness, my company decloaking its new website, and a fair dose of general uselessness. But here we are again.
One of the main things I tried to do last time was to point out the problems that hashbangs bring; but with some common sense, namely that sometimes you have to go down this route. Since hashbangs are a way of mitigating the problems associated with client-side routing (CSR), the issue becomes: what are the benefits of CSR?
CSR does one thing, and one thing only: it allows you to change content on a web page without forcing a complete page load. This can be used in a couple of significant ways:
- Protect client-side state (eg: long-running client side processes such as media players) from being disrupted during the page load
- To ensure that the client interface remains responsive through loading new content
In fact, the second is in some ways just a particular use of the first, although in practice they’re significantly different and so should be treated separately.
Enemy of the State
A page load wipes out a whole bunch of stuff: all your Javascript variables are gone, the whole DOM is thrown away and another one built (even if the vast majority of the resultant DOM is identical to the previous page), and any plugins and embedded media are unloaded. There are various things you might be doing that this will upset, but one jumps out immediately: playing audio.
I hope the music plays forever
If you have an audio player on a site, I think it’s pretty obvious that you don’t want the playback interrupted every time you click on a link or otherwise move around the site. If you put the audio player in the page and don’t use CSR, then page loads will do just that, and we can all get behind the idea that this is a bad thing.
Now back in April 2010 I, and a bunch of /dev/fort folk, came together to do some work for a client we cannot name, but which might have had something to do with the music industry. Naturally, one of the things we built into the prototype we made was an audio player; and being somewhat contrary folks, and because we conveniently had a Ben Firshman to hand, we decided we wanted an audio player that didn’t require client-side routing.
(Actually, this was pretty much an essential for us to do what we wanted in the time available; with three designers and nearly a dozen developers creating and refining things as fast as we could, the idea of sitting down at the beginning and building out a CSR framework, then requiring everyone create work that could be dropped into it, really didn’t appeal. By avoiding the issue, we were able to have people treat every page they built as just another normal webpage; and Ben got to do something cruel and unusual in Javascript, which always makes him happy.)
And Ben managed it. The player itself lived in a pop-out window, with a Javascript API that could be called from other windows on the site so they could contain the media player controls you expect, showing what was playing and where it had got to, synchronised across any and all windows and tabs you had open. Even better, when you played a video, the audio player would be paused and unpaused appropriately. Finally, if due to some confusion or bug more than one player window was opened, they’d talk amongst themselves to elect a single ‘master’ player that would take command.
So it’s possible; but I wouldn’t recommend it. Mainly, the pop-out window is a bit ugly, and may conflict with pop-up blockers thus preventing you from hearing any audio at all, page loads or not. Secondly, the code gets quite complicated, and doesn’t really seem worth it if your site’s main aim is to play music, as say The Hype Machine or thesixtyone are doing.
The only thing I can think of in its favour is that it provides an obvious screen location for the active component of the player (be it Flash or whatever), which might help me out because for reasons unknown The Hype Machine never actually plays me any music at all on Safari. But putting up with ugliness and code complexity so that I can debug your site for you really doesn’t seem like a good trade-off.
This is the point that Hype Machine’s Anthony Volodkin made when he weighed in on the matter. He pairs it with some comments about UX that are disingenuous but not entirely wrong, as we’ll see later.
There is another point I’d like to make here, though: both Hype Machine and thesixtyone behave terribly if you open multiple tabs or browser windows. The lack of centralised player means that each tab will play independently of and ignoring the others, which means multiple songs playing over each other. If you rely on tabbed browsing, this is a bit upsetting (almost as much as things looking like links but not actually acting like them; note in passing that this is nothing to do with CSR, and that all of Twitter’s links on their site are real links, albeit using hashbangs). On the plus side, Ben has been thinking of writing a library to support the single-controller model he built, which would make this kind of thing much easier.
Other stateful enterprises
While preparing this article, I made some notes on two other reasons you might want to persist the state of the page (except for the interface responsiveness issue we’ll come to shortly). However both ended up with a question mark by them; although they seem perfectly sound to me in principal, I can’t think of anything significant that both has a need for one of them and has a need for deep-linking. Since I’m mainly interested in the intersection of good effects and bad effects of CSR with hashbangs here, these aren’t so interesting, but I’ll list them briefly for completeness.
computation: if you’re doing lots of work in the client (perhaps in Web Workers, or by doing sliced computation using
setTimeout) then you don’t want the page to change underneath you. However in most cases the primary context isn’t going to change, so there’s no good reason for the URL to either, and you don’t need CSR so much as a way of stopping people from moving off the page, and there are already approaches to that. (Google Refine might do a fair amount of processing, but it doesn’t need a new URL except for each project; similarly Google Docs or similar only needs a new URL for each document. There’s probably some interesting corner cases here I haven’t considered, though.)games: it occurs to me that you may want to have a web game with addressable (and hence linkable and sharable) sections that needs to keep client-side state. I suppose strictly this becomes either an issue of computation or interface responsiveness (or just not wanting to reload a chunk of state from the server, local storage or cookies), and in any case I can’t think of anyone actually doing this at the moment. (Of course, I’ve never played Farmville; those kinds of games might well benefit.)
Don’t Make Me Think
There’s a huge problem with web browsers as they currently work, which is that at some point between clicking on a link and the next page loading there’s a period where the window behaves as neither of the pages. If you’re lucky, the next page loads really quickly, and you don’t notice it, but there’s always a period where you can’t click anything, and sometimes can’t even see anything. Let’s illustrate this by loading Dustin’s tweet that I demonstrated with last time.
We see the new page start to load; at this point in most browsers the old page is still responsive.
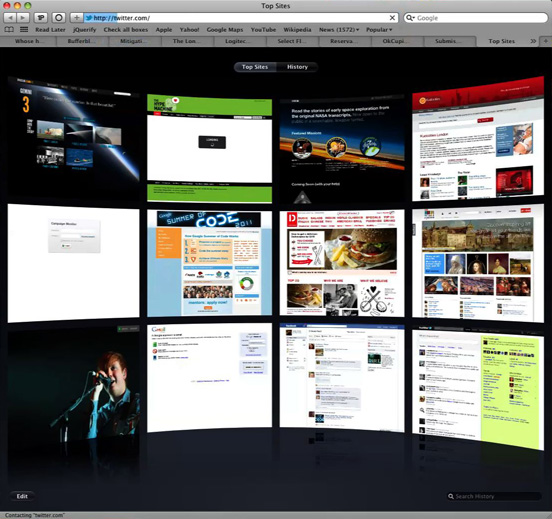
But then we get a white page briefly.
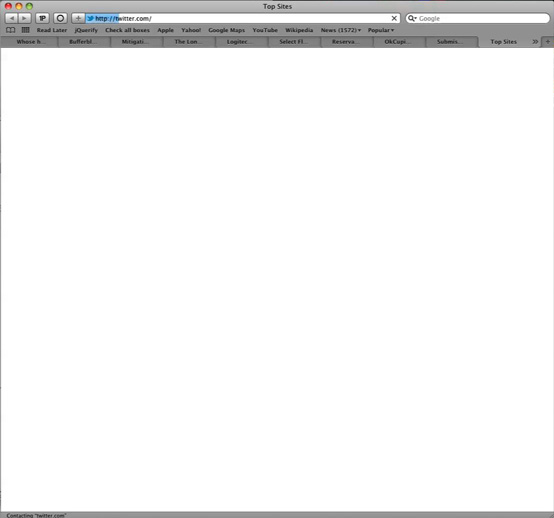
Then we get the Twitter HTML coming in…
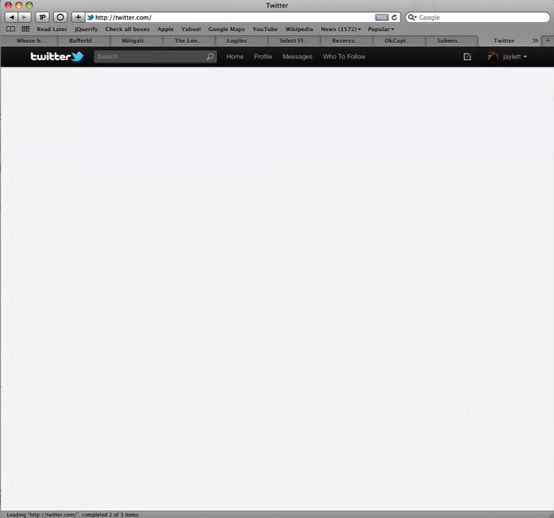
…and finally Twitter’s Javascript CSR loads the contents of my timeline.
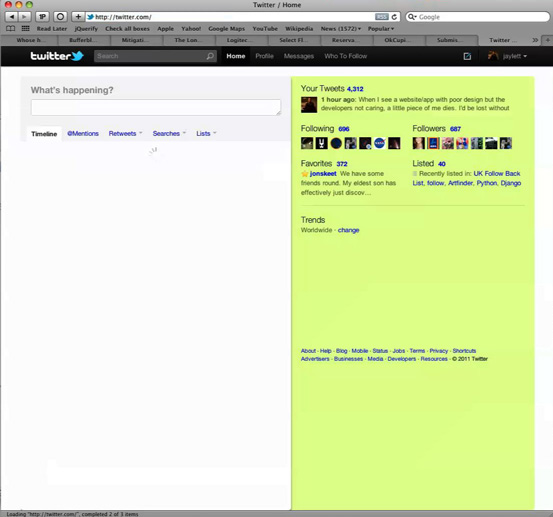
This actually happens in parallel to populating the right-hand side of the page, so the order that things appear isn’t fixed.
The entire thing took about a second for me as I recorded it as a video just now; it’s not a huge problem unless you have high latency or low bandwidth, and of course we’ve all learned to put up with it. However it is a genuine concern, as the longer something takes the more likely people are to get distracted during it.
I remember a much-touted point about an early version of the score writing software Sibelius was that every operation you could do, plus any redrawing of the screen, would be done in under a tenth of a second, which was supposed to be fast enough for people’s train of thought to be uninterrupted.
A brief diversion on distraction
I spent some time trying to find a reliable reference for the “tenth of a second” claim with no luck, although I’m guessing it related to the belief that it approximates the human reaction time (as noted critically by Wikipedia, for instance, although their article on mental chronometry does a better job). If you’re interested in human reaction time, there’s a 1982 article by Grice, Nullmeyer and Spiker which you can read for $12 or finding a student and buying them a beer.
Whatever the actual time required to interrupt a chain of thought, it’s clear that reducing the time of operations yields benefits. Google did some research in 2009 which can be taken to show that slower page loads result in less engagement with your site. (That’s not actually what it shows, but the paper itself is a single page without any detailed data to work with, and no discussion of confidence intervals; however it does show some impact on repeat engagement with Google Search based on slower page loads, and it marries sufficiently with common sense that we can probably go with the assumption that slow is bad until proven wrong.)
A brief diversion on latency
The Google paper talks about increasing the latency of search results, which informally means the time taken between doing something and seeing the result. Very roughly, an increase in latency is the same as increasing delay, as seen in this awesome cartoon.
Often when we’re talking about the web latency means network latency, which is the time between a computer (say a web server) sending some information (say a web page) and another computer (say your laptop) receiving it.
We usually measure network latency in milliseconds (ms), and they can range from very close to zero (for computers connected directly to yours) up to hundreds of milliseconds (say between one computer in London, UK and another in Perth, Australia). Between two computers about a mile apart in London, I see a round trip time (RTT) of about 22ms, giving the latency as about 11ms. From one of those computers to api.twitter.com gives an RTT of about 156ms, meaning 78ms latency.
And back to the topic at hand
Page loads on the web are generally slower than a tenth of a second; you’re only going to get that kind of speed out of the web for small pages from sites that are pretty close to you on the network (because of how brand new TCP connections work, you need a latency of under 25ms, and that’s not counting any time taken by the web server to process your request, or the web browser to render your page). Even 200ms is difficult to achieve for even small pages (50ms latency isn’t difficult when you’re within mainland US, but becomes difficult if you’ve got a lot of customers overseas and need to serve the traffic out of one data centre). Since Google were talking about 100-400ms showing a reduction in engagement, this has to be a serious consideration for anyone acting at scale (early-stage startups are more likely to be worried about getting more features up, and getting more users to play with them).
So the stage is set for us to introduce CSR to the problem. By asynchronously loading in new content rather than forcing an entire page load, we should be able to reduce the amount of data we have to transport, which might get us in under 400ms or even lower, but just as importantly, the interface remains completely functional throughout.
Don’t Make Me Wait
There’s a bit of an assumption going on here: that a responsive interface is enough to salve slow-loading content. In general this won’t be true (the fanciest interface probably won’t distract from taking ten minutes to load an image), but it would seem reasonable that there’s going to be a sweet spot where it’s better to spend time and effort on making the interface more responsive by using asynchronous loading than to spend the same time and effort trying to improve raw loading speeds.
After all, if a user decides they didn’t want something after they’ve asked for it but before it’s loaded, they just click somewhere else, and another async request will be fired off. Eventually something they’re interested in will load, unless you really can’t deliver content remotely fast at all.
A lot of people have grouped this under either “UX” or “performance”, which is unfortunate because they’re already both quite overloaded terms. I prefer to be precise about it, and say that the advantage here is around responsiveness, but we’re all getting at the same thing here. We want people to stay on our sites and keep on clicking around until, hopefully, we get to make some money, or kudos out of it, or at the very least get to stand next to celebrities and pretend we’re cool.
We’re not there yet
One of the dangers of imprecision is the conflation of different issues. You’ll note that CSR isn’t required for asynchronous loading of content at all; CSR is a way of making that content addressable by giving it a link that can be shared around. However not all content needs to be addressable.
I like to think of there being primary content, the “thing” you’re looking at, and secondary content which either relates to it in some way or is helpful in general. In terms of Twitter, primary content is the main timeline, searches, other people’s timelines, your followers and so on: the left-hand side of the web interface. Secondary content includes everything that goes in the right-hand panel: trending topics, favourites, lists you’ve been added to recently, and the conversation-ish view that pops up when you click on a tweet in the timeline. Secondary content can in some ways be considered to transclusion: including content within separate content, providing we talk quietly and don’t wake Ted Nelson.
When you don’t separate primary and secondary content, you wind up making mistakes; for instance, Ben Ward falls into this trap:
The reasons sites are using client-side routing is for performance: At the simplest, it’s about not reloaded an entire page when you only need to reload a small piece of content within it. Twitter in particular is loading lots, and lots of small pieces of content, changing views rapidly and continuously. Twitter users navigate between posts, pulling extra content related to each Tweet, user profiles, searches and so forth. Routing on the client allows all of these small requests to happen without wiping out the UI, all whilst simultaneously pulling in new content to the main Twitter timeline. In the vast majority of cases, this makes the UI more responsive.
This is misleading; the “small pieces of content” are generally pulled in without CSR, because the small requests aren’t the primary content of the page.
Here’s the thing. Primary content should be addressable; secondary content needn’t be. So secondary content isn’t going to benefit from CSR, and hashbangs don’t apply. (Twitter doesn’t make a hashbanged link for “your timeline with Dustin’s tweet highlighted”.) The only real similarity between them is that, with CSR, we can now load both asynchronously.
I argued last time you should consider not using CSR on “core objects” if you want a “safe” solution; these core objects are the same thing as primary content. But since CSR only benefits primary content, the conservative approach is never to use CSR at all. But we knew that; the interesting question is when you should use CSR.
The Tradeoff
The answer, as should be clear by now, relies on the relative importance of interface responsiveness compared the problems of limited addressability. It really needs considering on a case-by-case basis, and the trade-off relies on:
- how common an action is it?
- how fast is a complete page load compared to asynchronously pulling in just the new content, in the case of that action?
The former is down to a combination of UX design and user behaviour; with Twitter I know that I don’t often move far from the timeline, although I’d love to see hard data coming out from them about this.
For the latter, we have to start looking at performance. We’ll start by just looking at page sizes; but that’s for yet another separate article. I’ll try to complete it faster than this one.