So far I've found some interesting ways to suck in Widefinder. Let's find some more.
Analysing the lifecycle
I didn't really design the lifecycle of my processes; I was hoping I could just wing it by copying someone else and not think about it too much. Of course, when translating between languages, this isn't a great idea, because things behave differently; and not taking into account the new, enormous, size of the data set was a problem as well. 42 minutes isn't a terrible time, and I suspect that Python will have difficulty matching the 8-10 minutes of the top results, but we can certainly do better.
An obvious thing to do at this point is to look at how long the master, and each worker, actually spends doing the various tasks. What happens is that the master maps the file into memory, then forks the workers, each of which goes over the lines in its part of the file (with a little bit of subtlety to cope with lines that cross the boundaries), then serialises the results back over a pipe using cPickle. The master waits on each worker in turn, adding the partial results into the whole lot; then these results get run over to generate the elite sets for the output.
The following is taken from a run over the 10 million line subset. Other than providing logging to support this display, and removing the final output (but not the calculation), there were no other changes to the code.
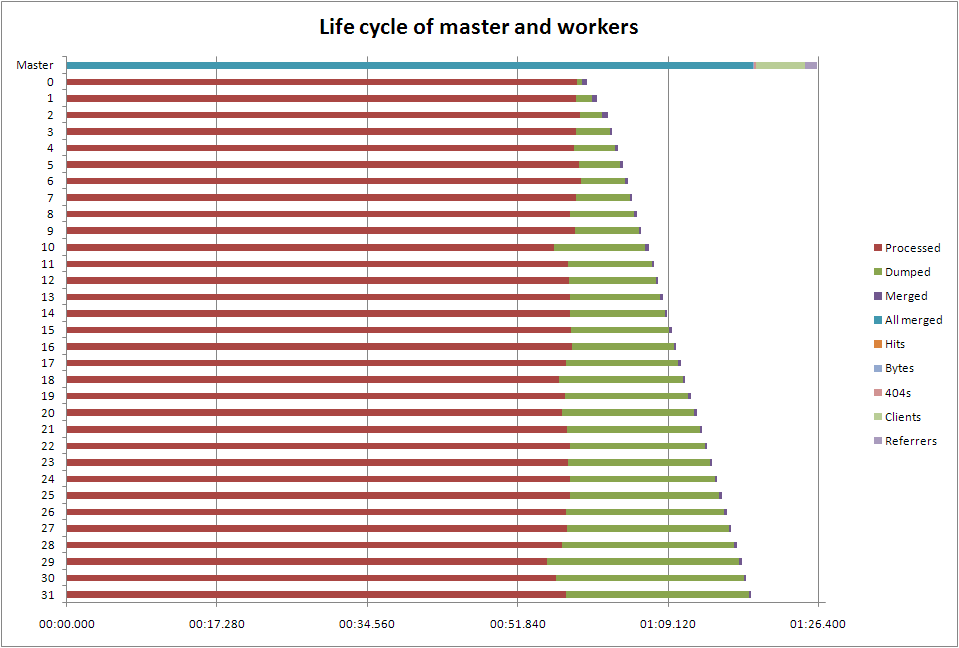
One thing immediately jumps out: because the workers aren't guaranteed to finish in the order we started them, we're wasting time by having the master process them in order. The time between the first worker to finish and the one we started first to finish is more than 20 seconds; in the full run we process about 20 times more data, so we'd expect that gap to become much larger. Out of order processing would seem to be worth looking at
It takes about half a second to dump, and another half a second to undump, data between each worker and the master: that's 30 seconds on this run, so again we might expect a significant penalty here. In another language we might try threads instead of processes, but Python isn't great at that. Alex Morega moved to temporary files using pickle, and saw an improvement over using whatever IPC pprocess uses. Temporary files would be worth investigating here; however it seems unlikely I can find a faster way of dumping my data than using cPickle.
Merging takes about 0.2s per worker, which isn't terribly significant. However the client and referrer reports both take significant time to process: nearly six seconds for the client report. It's been pointed out by Mauricio Fernandez that the current elite set implementation is O(nm log m) (choosing the m top of n items), on top of the at-best O(n) merges (the merges depend on the implementation of dictionaries in Python). Mauricio came up with a method he says is O(n log m), which would be worth looking at, although with m=10 as we have here, it won't make much difference.
You can't see it on this chart, but it looks like the line by line processing speed is constant across the run, which is really good news in scaling terms.
Other things to look at
There's the memory problem from before, where I could either run twice as many workers, in two batches (or overlapped, which should be more efficient), or I could make each worker split its workload down into smaller chunks, and memory map and release each one explicitly. The latter is easier to do, and also doesn't carry the impact of more workers.
Since on the T2000 the 32 bit versions of Python run faster than the 64 bit versions, making it so that each mapped chunk is under 2G would allow me to use the faster interpreter. That will actually fall out of the previous point, in this case.
I'm currently using a class I wrote that wraps the Python built-in dict; I should be able to extend it instead, and possibly take advantage of a Python 2.5 feature I was unaware of: __missing__. That's going to affect the processing of every single line, so even if the gains are slight, the total impact should be worthwhile.
In WF-1, Fredrik Lundh came up with some useful optimisations for Python. I'm already compiling my regular expressions, but I should roll in the others.
Tim's now installed the latest and greatest Sun compiler suite, so rebuilding Python 2.5 again with that might yield further speed improvements. He's also installed a SPARC-optimised Python 2.5, so perhaps that's already as fast as we're getting.
Other parallelisms
I missed WF 1 in LINQ the first time round, which mentioned PLINQ. The CTP (community technology preview) for this came out earlier this month, and Jon Skeet has been playing with it. PLINQ is exactly what I was talking about at the beginning of this series.