- Monday, 7 Apr 2008:
PNG Weirdness
- Friday, 28 Mar 2008:
Idiots
- Monday, 17 Mar 2008:
Advertising tech
- Thursday, 28 Feb 2008:
No shit, Amazon
- Thursday, 21 Feb 2008:
Are you worried yet?
- Tuesday, 29 Jan 2008:
I didn't tell you so
- Thursday, 20 Sep 2007:
EuroIA and Mr Pepys
- Friday, 3 Aug 2007:
Portable social networking
- Tuesday, 12 Jun 2007:
Hack day
- Tuesday, 17 Apr 2007:
Done deal
- Published at
- Monday 7th April, 2008
- Tagged as
- PNG
- Compression
- Doesn't that just make you go 'Oooh'?
So for my previous entry I had to create an image. Screenshot, paste into Photoshop, save as PNG. Done. Now a thumbnail: save-for-web, 50% scale, PNG. Done.
Erm.
-rw-rw-r-- 1 james james 16K 2008-04-07 13:42 error-message-large.png
-rw-rw-r-- 1 james james 33K 2008-04-07 13:43 error-message-thumb.png
Something's not quite right here: the half-sized thumbnail is taking up twice the space.
error-message-large.png: PNG image data, 1001 x 126, 8-bit/color RGB, non-interlaced
error-message-thumb.png: PNG image data, 500 x 63, 8-bit/color RGBA, non-interlaced
Okay, so maybe it's the colour space - RGBA is storing more data. Not, you know, twice as much data, but 32 bit rather than 24 bit is going to hurt in some way. So I go back in, resize the image in Photoshop, and save as PNG using the same options as for the large one.
-rw-rw-r-- 1 james james 26K 2008-04-07 13:45 error-message-small.png
error-message-small.png: PNG image data, 500 x 63, 8-bit/color RGB, non-interlaced
Okay, so reducing the colour space to 24 bit does what we expect: reduces the filesize by a quarter. It still doesn't explain why the original is so much smaller. Okay, well Photoshop also comes with ImageReady, so perhaps that can help.
| Input | Dimensions | Input size | Optimised size |
|---|
| large | 1001x126 | 16K | 15.29K |
| thumb | 500x63 | 32.1K | 32.12K |
| small | 500x63 | 25.7K | 25.36K |
| large resized | 500x63 | ~4K | 29.04K |
The last row is the interesting one: when resizing in ImageReady, it generates a 4K image... then optimises it to 29K.
For what it's worth, GIMP doesn't do any better. Anyone have any idea what's going on, or is it just pixies?
- Published at
- Friday 28th March, 2008
- Tagged as
I'll make this quick. Could the idiots in my life please leave?
Webcameron, David Cameron's video page, doesn't work; it is impossible for me to watch older videos on it, because the person who built it is an idiot who doesn't understand what a URI is, or what a Resource is, and probably needs beating round the head with a good book on the subject.
FeedDemon has always been slightly behind NetNewsWire in terms of ease-of-use, particularly in arranging feeds in folders (where FeedDemon would sometimes undo changes a day or two later for no obvious reason); now it's become utterly useless to me, as the synchronisation between the two doesn't actually synchronise, and the folders simply aren't being matched one product to the other. I have no idea why this is the case, but my bet is that they've each implemented synchronisation individually, rather than sharing code.
Firefox still only shuts down cleanly perhaps 20% of the time, meaning that I have to manually kill it to get restarts that preserve tabsets to work. Sometimes I forget, and having to remember to hard kill a program to get it to function isn't really acceptable. Yes, there's an extension to preserve tabsets for me better than Firefox itself manages; no, half the time it doesn't work with new versions of Firefox. My browsing experience is less pleasant than it was with early versions of Mozilla (say, 0.9 through to maybe 1.1). Don't even get me comparing it to the nineties.
I still cannot simply consume bundled (say, one subscription covering a group of studios) multimedia over the internet. Why is this so difficult? A back of the envelope calculation in 2006 said it could be done for under five million dollars, with a profit margin on top of a reasonable subscription. The crazy thing is that the AMPTP is now in a worse position on this kind of thing: failure to innovate weakens the hand of incumbants. Like that's news.
Windows has this stupid thing where it flashes a window's chrome and its taskbar representation whenever the window wants to 'notify' me of something. I don't appear to be able to turn it off, which is a problem when (a) notifications come for things that aren't important, like a transient error or - in the case of Filer windows - simply not being able to display the window contents yet; (b) modal dboxes are considered notifications, when everyone knows that they're used liberally in places they shouldn't be. I run maybe eight applications most of the time, many of which want to tell me something regularly. Most of them have system tray icons to tell me; however they also notify the window, so everything starts flashing and I can't concentrate on anything. There is a multiplicity of idiots at work here.
Okay, so I'm stunningly arrogant, but I really don't like it when my imagination outstrips reality to such a staggering degree. It's one thing to dream of flying cars, but quite another to think of things that are both technologically and economically viable and still wake up and discover they don't exist. Idiots: get to it. In the meantime I have to replace your shit with stuff that works, or find some way of chilling out. Neither should be necessary.
- Published at
- Monday 17th March, 2008
- Tagged as
- Google
- Advertising
- Technology
John Battelle makes a good point about (a) chasing Google and (b) the key to actually getting somewhere in the advertising market. Of course, this could be considered to be exactly the same as saying "it’s all very well coming up with funky new technology, but does it actually solve a real problem?". For various reasons I’m convinced there is still a huge amount of potential for new tech to offer value to the advertising industry. However I suspect it’s all in the hidden layer behind the scenes (back office, basically): the technology we have for delivering adverts right now is so far from being used to its full potential it does seem a little crazy to be trying to build yet more of it.
- Published at
- Thursday 28th February, 2008
- Tagged as
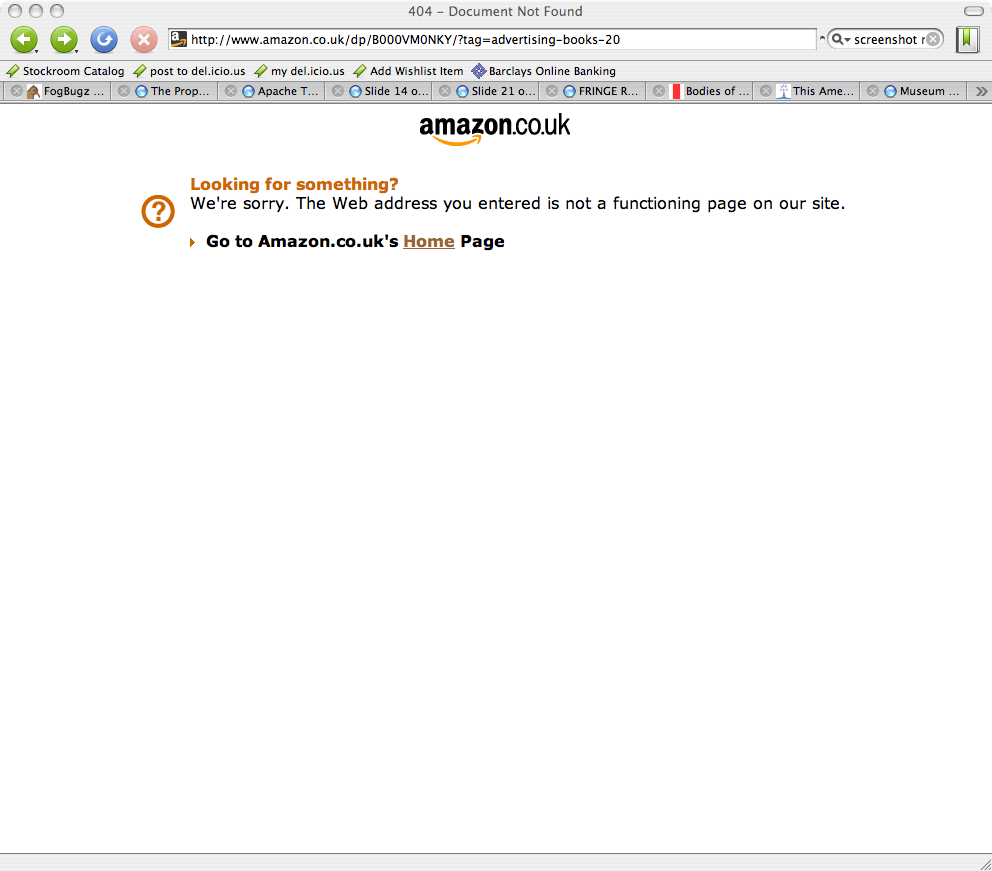
Every so often on the Amazon US site there's a nifty link that takes you to the same product on the Amazon UK site (maybe just because I'm based in the UK - who knows?). However it doesn't always work; fortunately what does work almost always these days is just changing the hostname from amazon.com to amazon.co.uk. I haven't quite got round to writing a bookmarklet for it, because it honestly is so easy to do anyway.
So it came as a bit of a surprise when changing this US link into this UK link didn't work (even though there is a product page for the item in question - it just has a different ASIN, probably because it's slightly different in a way that only Ubisoft really cares about). However that's not the big problem: not only did it not work, but it came up with a fairly unhelpful page.

Branding, but no chrome: this isn't really part of the Amazon UK site at all. In fact, all we'd need to make this into a helpful page would be a search box. Type in something useful and on you go. But no, as Amazon helpfully point out themselves: the Web address you entered is not a functioning page on our site.
Well, duh.
This is an example of what I'm beginning to think of as Apple trouble; when something simply works almost all of the time, you get disproportionately annoyed when it doesn't.
- Published at
- Thursday 21st February, 2008
- Tagged as
- Security
- Encryption
- Research
I haven’t had a chance to read the full paper yet, and I doubt it’s
practical for me to verify the results, but a team including Ed
Felten has figured out a way
round on-disk
encryption. The technique
sounds dangerously simple to implement, and even if it isn’t totally
reliable means you can’t trust on-disk encryption any more without
considering the hardware platform around it. Which is perhaps not
overly surprising; this is one reason I tend to avoid having nasty
things like CD/DVD ROM drives in machines unless they actually need
them. But now you need to go further: lock down the BIOS (ideally by
flashing it with a new one) so you can’t boot off USB or similar; and
somehow make it so you can’t easily remove the memory chips from the
computer. I suppose if you’re prepared to spend enough money, you
could simply make the entire unit unservicable, unexpandable, and
pretty much impregnable.
It’ll still get broken, though. As with so many things, when it comes
to security of data it really does seem like the only winning move is
not to play.
- Published at
- Tuesday 29th January, 2008
- Tagged as
- Foolishness
- Arrogance
- Google
Okay, so I don’t think I’ve ever actually said this in public, but we were all thinking it, right?
It doesn’t say much for the quality of those 150 people Google hires every week.
From Joel Spolsky.
- Published at
- Thursday 20th September, 2007
- Tagged as
- Information architecture
- Samuel Pepys
- History
- Inspiration
In a short while I’ll be heading off to Gatwick, and then to Barcelona
for EuroIA, the third European information
architecture summit. I’m not entirely sure what I’ll find there, but
one thing other people will find is a poster (or lots of bits of paper
taped to a wall, at least) trying to extract IA goodness from the life
of Samuel Pepys. I freely admit that it doesn’t make much sense, and
I’m not yet convinced that I’ve found anything out that’s useful to
other people, although I’ve learned a lot in the process. I’ll be
putting the images and drawings I made up on Flickr when I get back;
unfortunately I’ve run out of time in the mad push to print onto
tracing paper, wrestle our A3 colour printer into obediance, and other
fun things.
If you’re there over the next few days, come and say hi, and try not
to ask me anything really hard about the 17th Century - I never
thought I’d say it, but I’m kind of sick of it. At least for the time
being.
- Published at
- Friday 3rd August, 2007
- Tagged as
- Social networking
- Portable social networking
- Python
- Laziness
There's been a fair amount of discussion recently about the idea of portable social networking - that when you sign up to a new site, it should be really easy to pull your contacts and so on from whatever you've used before. Various people are attacking this problem, in various ways - in June, at Hack Day, I took the external route of writing a library you can use to pull down all your contact lists from different social networks, merge them, and list the results. It wasn't very pretty, and was really a demonstration of what could be done more than anything else.
Since then, a couple of people have expressed interest in it; either because they want to use it directly, or because they want to check how other people have tackled this problem before writing their own. You can download the python source code: psnlib.
I'm lazy at the best of times, so there:
- isn't an autoloader for the social network-specific plugins (it's about five lines of python, and I have it somewhere if anyone really wants)
- are unit tests (because it was quicker to write that way; however some of them have hard-coded specifics like who the first contact in my flickr list is)
- are my API keys, allocated for Hack Day, still in the source
There's probably some other stuff wrong as well; but you might find it useful nonetheless.
- Published at
- Tuesday 12th June, 2007
- Tagged as
So Hack Day is just around the corner - a few
more days and we’ll all be rolling in APIs, pizzas, the fluff that
gathers anywhere that several hundred people are, and so on.
I have no idea what I’ll be doing yet; I had a daft idea which turned
out to be impractical without a lot of painful setup, and another idea
which is just daft (and so probably just about worth doing). Things
are floating around in my head, and with luck something will pop out
just in time for me to pull it off. Twenty-four hours is a long time,
and I do my best thinking at night anyway.
- Published at
- Tuesday 17th April, 2007
- Tagged as
I’ve never really abused job perks. Sure, I may have mailed out some personal items using the company franking system, and I might have done some photocopying for a launch party for my book, but I haven’t charged undue things on expenses, or stolen the phone system or anything.
Well all that has changed: the top ten hits on Google for "James Aylett" are my homepage (twice, for complex reasons), two pages from The Uncertainty Division, one from Amazon, the two previously mentioned of random things I’ve done with my friends, two from Talk To Rex, and the ad:tech one. The Bath student has dropped off the front page!
Coincidence?